![[S] Subversion](/images/svn-name-banner.svg)
If you are contributing to the Subversion project, please read this first.
Although Subversion was originally sponsored and hosted by CollabNet (https://www.collab.net/), it's a true open-source project under the Apache License, Version 2.0. A number of Subversion's developers are paid by their employers to improve Subversion, while many others are simply excellent volunteers who are interested in building a better version control system.
The community exists mainly through mailing lists and a Subversion repository. To participate:
Join the "dev", "commits", and "announce" mailing lists. The dev list, dev@subversion.apache.org, is where almost all discussion takes place. All development questions should go there, though you might want to check the list archives first. The "commits" list receives automated commit emails. See https://subversion.apache.org/mailing-lists.html for details.
Get a copy of the latest development sources from
https://svn.apache.org/repos/asf/subversion/trunk/
New development always takes place on trunk. Bugfixes,
enhancements, and new features are backported from there to the
various release branches.
For several years, the Subversion Community meet in Berlin for a Hackathon once a year: 2016, 2015, 2014, 2013, 2012, 2011 and 2010 [linked from archive.org, some media links do not work].
There are many ways to join the project, either by writing code, or by testing and/or helping to manage the bug database. If you'd like to contribute, then look at:
The bugs/issues database https://issues.apache.org/jira/projects/SVN/issues
To submit code, simply send your patches to dev@subversion.apache.org. No, wait, first read the rest of this file, then start sending patches to dev@subversion.apache.org. :-)
To help manage the issues database, read over the issue summaries, looking and testing for issues that are either invalid, or are duplicates of other issues. Both kinds are very common, the first because bugs often get unknowingly fixed as side effects of other changes in the code, and the second because people sometimes file an issue without noticing that it has already been reported. If you are not sure about an issue, post a question to dev@subversion.apache.org. ("Subversion: We're here to help you help us!")
Another way to help is to set up automated builds and test suite runs of Subversion on some platform, and have the output sent to the notifications@subversion.apache.org mailing list. See more details at the mailing lists page.
Finally, despite the online nature of the Subversion project and the human contact abstraction that results from that fact, it is important to realize that there are real people at the end of all contributions. Treat all other community members as you would expect to be treated. Review the contribution, not the contributor; don't annoy others, and don't become easily annoyed yourself.
Design
A design spec was written in June 2000, and is a bit out of date. But it still gives a good theoretical introduction to the inner workings of the repository, and to Subversion's various layers.
API Documentation
See the section on the public API documentation for more information.
Delta Editors
Karl Fogel wrote a chapter for O'Reilly's 2007 book Beautiful Code: Leading Programmers Explain How They Think covering the design and use of Subversion's delta editor interface.
Network Protocols
The WebDAV Usage document is an introduction to Subversion's DAV network protocol, which is an extended dialect of HTTP and uses URLs beginning with "http://" or "https://".
The SVN Protocol document contains a formal description of Subversion ra_svn network protocol, which is a custom protocol on port 3690 (by default), whose URLs begin with "svn://" or "svn+ssh://".
User Manual
Version Control with Subversion is a book published by O'Reilly that shows in detail how to effectively use Subversion. The text of the book is free, and is actively being revised. On-line versions are available at https://svnbook.red-bean.com/. The XML source and translations to other languages are maintained in their own repository at https://sourceforge.net/projects/svnbook/.
System notes
A lot of the design ideas for particular aspects of the system have been documented in individual files in the notes/ directory.
Before you can contribute code, you'll need to familiarize yourself with the existing code base and interfaces.
Check out a copy of Subversion (anonymously, if you don't yet have an account with commit access) — so you can look at the code.
Within 'subversion/include/' are a bunch of header files with huge doc comments. If you read through these, you'll have a pretty good understanding of the implementation details. Here's a suggested perusal order:
the basic building blocks: svn_string.h, svn_error.h, svn_types.h
the critical interface: svn_delta.h
client-side interfaces: svn_ra.h, svn_wc.h, svn_client.h
the repository and versioned filesystem: svn_repos.h, svn_fs.h
Subversion tries to stay portable by using only the C89/C90 dialect of ANSI/ISO C and by using the Apache Portable Runtime (APR) library. APR is the portability layer used by the Apache httpd server, and more information can be found at https://apr.apache.org/.
Because Subversion depends so heavily on APR, it may be hard to understand Subversion without first glancing over certain header files in APR (look in 'apr/include/'):
memory pools: apr_pools.h
filesystem access: apr_file_io.h
hashes and arrays: apr_hash.h, apr_tables.h
Subversion also tries to deliver reliable and secure software. This can only be achieved by developers who understand secure programming in the C programming language. Please see 'notes/assurance.txt' for the full rationale behind this. Specifically, you should make it a point to carefully read David Wheeler's Secure Programming (as mentioned in 'notes/assurance.txt'). If at any point you have questions about the security implications of a change, you are urged to ask for review on the developer mailing list.
A rough guide to the source tree:
doc/
User and Developer documentation.
tools/
Stuff that works with Subversion, but that Subversion doesn't
depend on. Code in tools/ is maintained collectively by the
Subversion project, and is under the same open source copyright as
Subversion itself.
contrib/
Stuff that works with Subversion, but that Subversion doesn't
depend on, and that is maintained by individuals who may or may
not participate in Subversion development. Code in contrib/ is
open source, but may have a different license or copyright holder
than Subversion itself.
subversion/
Source code to Subversion itself (as opposed to external
libraries).
subversion/include/
Public header files for users of Subversion libraries.
subversion/include/private/
Private header files shared internally by Subversion libraries.
subversion/libsvn_fs/
The versioning "filesystem" API.
subversion/libsvn_repos/
Repository functionality built around the `libsvn_fs' core.
subversion/libsvn_delta/
Common code for tree deltas, text deltas, and property deltas.
subversion/libsvn_wc/
Common code for working copies.
subversion/libsvn_ra/
Common code for repository access.
subversion/libsvn_client/
Common code for client operations.
subversion/svn/
The command line client.
subversion/tests/
Automated test suite.
The Subversion project strongly prefers that active development happens in the common trunk. Changes made to trunk have the highest visibility and get the greatest amount of exercise that can be expected from unreleased code. For this to be beneficial to everyone, though, our trunk is expected at all times to be stable. It should build. It should work. It might not be release-ready, but it should certainly be test-suite ready.
We also strongly prefer to see large changes broken up into several, smaller, logical commits — each of which is expected to meet the aforementioned requirements of stability.
That said, we understand that it can be nearly impossible to apply all these policies to particularly large changes (new features, sweeping code reorganizations, etc.). It is in those situations that you might consider using a custom branch dedicated to your development task. The following are some guidelines to make your branch-based development work go smoothly.
There's nothing particularly complex about branch-based development. You make a branch from the trunk (or from whatever branch best serves as both source and destination for your work), and you do your work on it. Subversion's merge tracking feature has greatly helped to reduce the sort of mental overhead required to work in this way, so making good use of that feature (by using Subversion 1.5 or newer clients, and by performing all merges to and from the roots of branches) is highly encouraged.
For our policy on log messages for your branch, please note the section on writing log messages.
If you're working on a feature or bugfix in stages involving multiple commits, and some of the intermediate stages aren't stable enough to go on trunk, then create a temporary branch in /branches. There's no need to ask — just do it. It's fine to try out experimental ideas in a temporary branch, too. And all the preceding applies to partial as well as full committers. It even applies to committers of other ASF projects, but please talk to us (on dev@)—introduce yourself and the problem you plan to work on.
When you're done with the branch — when you've either merged it to trunk or given up on it — please remember to remove it.
See also the section on partial commit access for our policy on offering commit access to experimental branches.
For branches you expect to be longer-lived, we recommend the creation and regular updating of a file in the root of your branch named BRANCH-README. Such a file provides you with a great, central place to describe the following aspects of your branch:
The basic purpose of your branch: what bug it exists to fix, or feature to implement; what issue number(s) it relates to; what list discussion threads surround it; what design docs exists to describe the situation.
What style of branch management you are using: is this a feature branch that will regularly be kept in sync with its parent branch and ultimately reintegrated back to that parent branch? Is it a fork that is not expected to be merged back to its parent branch in the foreseeable future? Does it relate to any other branches?
What tasks remain for you to accomplish on your branch? Are those tasks claimed by someone? Do they need more design input? How can others help you?
Here is an example BRANCH-README file that demonstrates what we're talking about:
This branch exists for the resolution of issue #8810, per the ideas documented in /trunk/notes/frobnobbing-feature.txt. It is a feature branch, receiving regular sync merges from /trunk, and expected to be reintegrated back thereto. TODO: * compose regression tests [DONE] * add frob identification logic [STARTED (fitz)] * add nobbing bits []
Why all the fuss? Because this project idealizes communication and collaboration, understanding that the latter is more likely to happen when the former is a point of emphasis.
Just remember when you merge your branch back to its source to delete the BRANCH-README file.
Every function, whether public or internal, must start out with a documentation comment that describes what the function does. The documentation should mention every parameter received by the function, every possible return value, and (if not obvious) the conditions under which the function could return an error.
For internal documentation put the parameter names in upper case in the doc string, even when they are not upper case in the actual declaration, so that they stand out to human readers.
For public or semi-public API functions, the doc string should go above the function in the .h file where it is declared; otherwise, it goes above the function definition in the .c file.
For structure types, document each individual member of the structure as well as the structure itself.
For actual source code, internally document chunks of each function, so that an someone familiar with Subversion can understand the algorithm being implemented. Do not include obvious or overly verbose documentation; the comments should help understanding of the code, not hinder it.
For example:
/*** How not to document. Don't do this. ***/
/* Make a foo object. */
static foo_t *
make_foo_object(arg1, arg2, apr_pool_t *pool)
{
/* Create a subpool. */
apr_pool_t *subpool = svn_pool_create(pool);
/* Allocate a foo object from the main pool */
foo_t *foo = apr_palloc(pool, sizeof(*foo));
...
}
Instead, document decent sized chunks of code, like this:
/* Transmit the segment (if its within the scope of our concern). */
SVN_ERR(maybe_crop_and_send_segment(segment, start_rev, end_rev,
receiver, receiver_baton, subpool));
/* If we've set CURRENT_REV to SVN_INVALID_REVNUM, we're done
(and didn't ever reach END_REV). */
if (! SVN_IS_VALID_REVNUM(current_rev))
break;
/* If there's a gap in the history, we need to report as much
(if the gap is within the scope of our concern). */
if (segment->range_start - current_rev < 1)
{
svn_location_segment_t *gap_segment;
gap_segment = apr_pcalloc(subpool, sizeof(*gap_segment));
gap_segment->range_end = segment->range_start - 1;
gap_segment->range_start = current_rev + 1;
gap_segment->path = NULL;
SVN_ERR(maybe_crop_and_send_segment(gap_segment, start_rev, end_rev,
receiver, receiver_baton,
subpool));
}
Read over the Subversion code to get an overview of how documentation looks in practice; in particular, see subversion/include/*.h for doxygen examples.
We use the Doxygen format for public interface documentation. This means anything that goes in a public header file. The generated documentation is published on the web site for the latest and some earlier Subversion sources.
We use only a small portion of the available doxygen commands to markup our source. When writing doxygen documentation, the following conventions apply:
@a, and type and macro names with
@c.<tt>...</tt> to display multiple words
and @p to display only one word in typewriter font.TRUE, FALSE and
NULL should be in all caps.@defgroup and @{...@}.See the Doxygen manual for a complete list of commands.
To get the latest source code, run:
svn checkout https://svn.apache.org/repos/asf/subversion/trunk/ svn-trunk
and follow the instructions in the INSTALL file. (If you do not have an svn client, download a source tarball.)
If your patch implements a new feature, or changes large amounts of code, please remember to discuss it on the dev@ list first. Please wait some time for a response, as not everyone is online all the time. That is so the community can express concerns with and suggest improvements for the proposed feature or implementation details as soon as possible—it is always better for all parties if that feedback is provided sooner (even before any code is written) rather than later.
If you have any questions about the patch, please feel free to ask them on dev@.
Mail patches to dev@subversion.apache.org, starting the subject line with [PATCH]. This helps our patch manager spot patches right away. For example:
Subject: [PATCH] fix for rev printing bug in svn status
If the patch addresses a particular issue, include the issue number as well: "[PATCH] issue #1729: ...". Developers who are interested in that particular issue will know to read the mail.
A patch submission should contain one logical change; please don't mix N unrelated changes in one submission — send N separate emails instead.
Generate the patch using svn diff -x-p from the top of a Subversion trunk working copy. If the file you're diffing is not under revision control, you can achieve the same effect by using diff -u.
Please include a log message with your patch. A good log message helps potential reviewers understand the changes in your patch, and increases the likelihood that it will be applied. You can put the log message in the body of the email, or at the top of the patch attachment (see below). Either way, it should follow the guidelines given in Writing log messages, and be enclosed in triple square brackets, like so:
[[[
Fix issue #1729: Don't crash because of a missing file.
* subversion/libsvn_ra_ansible/get_editor.c
(frobnicate_file): Check that file exists before frobnicating.
]]]
(The brackets are not actually part of the log message, they're just a way to clearly mark off the log message from its surrounding context.)
If possible, send the patch as an attachment with a mime-type of
text/x-diff, text/x-patch, or text/plain.
Most people's mailreaders can display those inline, and having the patch as an
attachment allows them to extract the patch from the message conveniently.
Never send patches in archived or compressed form (e.g., tar, gzip, zip, bzip2),
because that prevents people from reviewing the patch directly in
their mailreaders.
If you can't attach the patch with one of these mime-types, or if the patch is very short, then it's okay to include it directly in the body of your message. But watch out: some mail editors munge inline patches by inserting unasked-for line breaks in the middle of long lines. If you think your mail software might do this, then please use an attachment instead.
If the patch implements a new feature, make sure to describe the feature completely in your mail; if the patch fixes a bug, describe the bug in detail and give a reproduction recipe. An exception to these guidelines is when the patch addresses a specific issue in the issues database — in that case, just refer to the issue number in your log message, as described in Writing log messages.
It is normal for patches to undergo several rounds of feedback and change before being applied. Don't be discouraged if your patch is not accepted immediately — it doesn't mean you goofed, it just means that there are a lot of eyes looking at every code submission, and it's a rare patch that doesn't have at least a little room for improvement. After discussing people's responses to your patch, make the appropriate changes and resubmit, wait for the next round of feedback, and lather, rinse, repeat, until some committer applies it. You can avoid some iterations by reviewing and applying the project's Coding Conventions to your patch before submitting it.
If you don't get a response for a while, and don't see the patch applied, it may just mean that people are really busy. Go ahead and repost, and don't hesitate to point out that you're still waiting for a response. One way to think of it is that patch management is highly parallizable, and we need you to shoulder your share of the management as well as the coding. Every patch needs someone to shepherd it through the process, and the person best qualified to do that is the original submitter.
Committers in the Subversion project are those folks to whom the right to directly commit changes to our version controlled resources has been granted. The project is meritocratic, which means (among other things) that project governance is handled by those who do the work. There are two types of commit access: full and partial. Full means anywhere in the tree, partial means only in that committer's specific area(s) of expertise. While every contribution is valued regardless of its source, not every person who contributes code to Subversion will earn commit access.
The COMMITTERS file lists all committers, both full and partial, and says the domains for each partial committer.
After someone has successfully contributed a few non-trivial patches, some full committer, usually whoever has reviewed and applied the most patches from that contributor, proposes them for commit access. This proposal is sent only to the other full committers -- the ensuing discussion is private, so that everyone can feel comfortable speaking their minds. Assuming there are no objections, the contributor is granted commit access. The decision is made by consensus; there are no formal rules governing the procedure, though generally if someone strongly objects the access is not offered, or is offered on a provisional basis.
The primary criterion for full commit access is good judgment.
You do not have to be a technical wizard, or demonstrate deep knowledge of the entire codebase, to become a full committer. You just need to know what you don't know. If your patches adhere to the guidelines in this file, adhere to all the usual unquantifiable rules of coding (code should be readable, robust, maintainable, etc.), and respect the Hippocratic Principle of "first, do no harm", then you will probably get commit access pretty quickly. The size, complexity, and quantity of your patches do not matter as much as the degree of care you show in avoiding bugs and minimizing unnecessary impact on the rest of the code. Many full committers are people who have not made major code contributions, but rather lots of small, clean fixes, each of which was an unambiguous improvement to the code. (Of course, this does not mean the project needs a bunch of very trivial patches whose only purpose is to gain commit access; knowing what's worth a patch post and what's not is part of showing good judgement :-) .)
To assist developers in discovering new committers, we record patches and other contributions in a special crediting format, which is then parsed to produce a browser-friendly contribution list, updated nightly. If you're thinking of proposing someone for commit access and want to look over all their changes, that contribution list might be the most convenient place to do it.
A full committer sponsors the partial committer. Usually this means the full committer has applied several patches to the same area from the proposed partial committer, and realizes things would be easier if the person were just committing directly. It is customary and recommended for the sponsor to float the prospect by private@ before issuing an invitation, but not required; sponsors are trusted to use good judgement.
The sponsor watches the partial committer's first few commits to ensure everything's going smoothly.
Patches submitted by a partial committer may be committed by that committer even if they are outside that person's domain. This requires approval (often expressed as a +1 vote) from at least one full committer. In such a case, the approval should be noted in the log message, like so:
Approved by: lundblad
Any full committer may offer anyone commit access to an experimental branch at any time. It is not necessary that the experimental branch have a high likelihood of being merged to trunk (although that's always a good goal to aim for). It's just as important that the full committer — all the full committers, actually — view such branches as training grounds for new developers, by giving feedback on the commits. The goal of these branches is both to get new code into Subversion and to get new developers into the project. See also the section on lightweight branches, and this mail:
https://svn.haxx.se/dev/archive-2007-11/0848.shtml From: Karl Fogel <kfogel@red-bean.com> To: dev@subversion.tigris.org Subject: branch liberalization (was: Elego tree conflicts work) Date: Tue, 20 Nov 2007 10:49:38 -0800 Message-Id: <87y7cswy4d.fsf@red-bean.com>
When a tool is accepted into the contrib/ area, we automatically offer its author partial commit access to maintain the tool there. Any full committer can sponsor this. Usually no discussion or vote is necessary, though if there are objections then the usual decision-making procedures apply (attempt to reach consensus first, then vote among the full committers if consensus cannot be reached).
Code under contrib/ must be open source, but need not have the same license or copyright holder as Subversion itself.
Any committer, whether full or partial, may commit fixes for obvious typos, grammar mistakes, and formatting problems wherever they may be — in the web pages, API documentation, code comments, commit messages, etc. We rely on the committer's judgement to determine what is "obvious"; if you're not sure, just ask.
Whenever you invoke the "obvious fix" rule, please say so in the log message of your commit. For example:
------------------------------------------------------------------------ r32135 | stylesen | 2008-07-16 10:04:25 +0200 (Wed, 16 Jul 2008) | 8 lines Update "check-license.py" so that it can generate license text applicable to this year. Obvious fix. * tools/dev/check-license.py (NEW_LICENSE): s/2005/2008/ ------------------------------------------------------------------------
Subversion is part of the ASF, and shares the same repository with 100+ other ASF projects. While people who are committers on those projects are not considered either full or partial committers to Subversion, they are welcome to commit obvious fixes, as well as patches they submitted—provided the patches have received a +1 from a full committer (or from a partial committer within his domain). In both cases, please follow our log message guidelines.
The role of the Release Manager in the Subversion project is to handle the process of getting code stabilized, packaged and released to the general public. If we were building planes, the RM would be the guy looking at the construction checklists, painting the airline logo on the fuselage, and delivering the finished unit to the customer.
As such, there is no real development associated with being an RM. All the work you have to do is non-coding: coordinating people, centralizing information, and being the public voice announcing new stable releases. A lot of the tasks that the RM has to do are repetitive, and not automated either because nobody has broken down and written the tools yet, or because the tasks require human validation that makes automation a little superfluous. You can read more about the release process in the section Making Subversion Releases.
You may be thinking at this stage that the RM's duty is unglamorous, and you are kinda right. If you are looking for a position within the project that will bring fame and fortune, you're better off implementing stuff that really needs to be done on trunk. If you're looking for something that really helps people who don't care about releases focus on code, then RMing is for you.
In an effort to encourage wider dispersion of release management
knowledge, the RM role is currently rotating among various
victims volunteers.
Subversion usually has a Patch Manager, whose job is to watch the dev@ mailing list and make sure that no patches "slip through the cracks".
This means watching every thread containing "[PATCH]" mails, and taking appropriate action based on the progress of the thread. If the thread resolves on its own (because the patch gets committed, or because there is consensus that the patch doesn't need to be applied, or whatever) then no further action need be taken. But if the thread fades out without any clear decision, then the patch needs to be saved in the issue tracker. This means that a summary of any discussion threads around that patch, and links to relevant mailing list archives, will be added to some issue in the tracker. For a patch which addresses an existing issue tracker item, the patch is saved to that item. Otherwise, a new issue of the correct type — 'DEFECT', 'FEATURE', or 'ENHANCEMENT' (not 'PATCH') — is filed, the patch is saved to that new issue, and the "patch" keyword is recorded on the issue.
The Patch Manager needs a basic technical understanding of Subversion, and the ability to skim a thread and get a rough understanding of whether consensus has been reached, and if so, of what kind. It does not require actual Subversion development experience or commit access. Expertise in using one's mail reading software is optional, but recommended :-).
The current Patch Manager is: Gavin 'Beau' Baumanis <gavin@thespidernet.com>.
Subversion's code and headers files are segregated along a couple of key lines: library-specific vs. inter-library; public vs. private. This separation is done primarily because of our focus on proper modularity and code organization, but also because of our promises as providers and maintainers of a widely adopted public API. As you write new functions in Subversion, you'll need to carefully consider these things, asking some questions of yourself as you go along:
"Are the consumers of my new code local to a particular source code file in a single library?" If so, you probably want a static function in that same source file.
"Is my new function of the sort that other source code within this library will need to use, but nothing *outside* the library?" If so, you want to use a non-static, double-underscore-named function (such as svn_foo__do_something), with its prototype in the appropriate library-specific header file.
"Will my code need to be accessed from a different library?" Here you have some additional questions to answer, such as "Should my code live in the original library I was going to put it in, or should it live in a more generic utility library such as libsvn_subr?" Either way, you're now looking at using an inter-library header file. But see the next question before you decide which one...
"Is my code such that it has a clean, maintainable API that can reasonably be maintained in perpetuity and brings value to the Subversion public API offering?" If so, you'll be adding prototypes to the public API, immediately inside subversion/include/. If not, double-check your plans -- maybe you haven't chosen the best way to abstract your functionality. But sometimes it just happens that libraries need to share some function that is arguably of no use to other software besides Subversion itself. In those cases, use the private header files in subversion/include/private/.
Subversion uses ANSI C, and follows the GNU coding standards, except that we do not put a space between the name of a function and the opening parenthesis of its parameter list. Emacs users can just load svn-dev.el to get the right indentation behavior (most source files here will load it automatically, if `enable-local-eval' is set appropriately).
Read https://www.gnu.org/prep/standards.html for a full description of the GNU coding standards. Below is a short example demonstrating the most important formatting guidelines, including our no-space-before-param-list-paren exception:
char * /* func type on own line */
argblarg(char *arg1, int arg2) /* func name on own line */
{ /* first brace on own line */
if ((some_very_long_condition && arg2) /* indent 2 cols */
|| remaining_condition) /* new line before operator */
{ /* brace on own line, indent 2 */
arg1 = some_func(arg1, arg2); /* NO SPACE BEFORE PAREN */
} /* close brace on own line */
else
{
do /* format do-while like this */
{
arg1 = another_func(arg1);
}
while (*arg1);
}
}
In general, be generous with parentheses even when you're sure about the operator precedence, and be willing to add spaces and newlines to avoid "code crunch". Don't worry too much about vertical density; it's more important to make code readable than to fit that extra line on the screen.
We're using page breaks (the Ctrl-L character, ASCII 12) for section boundaries in both code and plaintext prose files. Each section starts with a page break, and immediately after the page break comes the title of the section.
This helps out people who use the Emacs page commands, such as `pages-directory' and `narrow-to-page'. Such people are not as scarce as you might think, and if you'd like to become one of them, then add (require 'page-ext) to your .emacs and type C-x C-p C-h sometime.
For error messages the following conventions apply:
Provide specific error messages only when there is information to add to the general error message found in subversion/include/svn_error_codes.h.
Messages start with a capital letter.
Try keeping messages below 70 characters.
Don't end the error message with a period (".").
Don't include newline characters in error messages.
Quoting information is done using single quotes (e.g. "'some info'").
Don't include the name of the function where the error occurs in the error message. If Subversion is compiled using the '--enable-maintainer-mode' configure-flag, it will provide this information by itself.
When including path or filenames in the error string, be sure to quote them (e.g. "Can't find '/path/to/repos/userfile'").
When including path or filenames in the error string, be sure to convert them using svn_dirent_local_style() before inclusion (since paths passed to and from Subversion APIs are assumed to be in canonical form).
Don't use Subversion-specific abbreviations (e.g. use "repository" instead of "repo", "working copy" instead of "wc").
If you want to add an explanation to the error, report it followed by a colon and the explanation like this:
"Invalid " SVN_PROP_EXTERNALS " property on '%s': "
"target involves '.' or '..'".
Suggestions or other additions can be added after a semi-colon, like this:
"Can't write to '%s': object of same name already exists; remove "
"before retrying".
Try to stay within the boundaries of these conventions, so please avoid separating different parts of error messages by other separators such as '--' and others.
Also read about Localization.
(This assumes you already basically understand how APR pools work; see apr_pools.h for details.)
Applications using the Subversion libraries must call apr_initialize() before calling any Subversion functions.
Subversion's general pool usage strategy can be summed up in two principles:
The call level that created a pool is the only place to clear or destroy that pool.
When iterating an unbounded number of times, create a subpool before entering the iteration, use it inside the loop and clear it at the start of each iteration, then destroy it after the loop is done, like so:
apr_pool_t *iterpool = svn_pool_create(scratch_pool);
for (i = 0; i < n; ++i)
{
svn_pool_clear(iterpool);
do_operation(..., iterpool);
}
svn_pool_destroy(iterpool);
Supporting the above rules, we use the following pool names as conventions to represent various pool lifetimes:
result_pool: The pool in which the output of a function
should be allocated. A result pool declaration should always
be found in a function argument list, and never inside a local block. (But
not all functions need or have result pools.)
scratch_pool: The pool in which all function-local data
should be allocated. This pool is also provided by the caller, who may
choose to clear this pool immediately when control returns to it.
iterpool: An iteration pool, used inside loops,
as per the above example.
(Note: Some legacy code uses a single pool function argument,
which operates as both the result and scratch pools.)
By using an iterpool for loop-bounded data, you ensure O(1) instead of O(N) memory leakage should the function return abruptly from within the loop (say, due to error). That's why you shouldn't make a subpool for data which persists throughout a function, but instead should use the pool passed in by the caller. That memory will be reclaimed when the caller's pool is cleared or destroyed. If the caller is invoking the callee in a loop, then trust the caller to take care of clearing the pool on each iteration. The same logic propagates all the way up the call stack.
The pool you use also helps readers of the code understand object lifetimes. Is a given object used only during one iteration of the loop, or will it need to last beyond the end of the loop? For example, pool choices indicate a lot about what's going on in this code:
apr_hash_t *persistent_objects = apr_hash_make(result_pool);
apr_pool_t *iterpool = svn_pool_create(scratch_pool);
for (i = 0; i < n; ++i)
{
const char *intermediate_result;
const char *key, *val;
svn_pool_clear(iterpool);
SVN_ERR(do_something(&intermediate_result, ..., iterpool));
SVN_ERR(get_result(intermediate_result, &key, &val, ...,
result_pool));
apr_hash_set(persistent_objects, key, APR_HASH_KEY_STRING, val);
}
svn_pool_destroy(iterpool);
return persistent_objects;
Except for some legacy code, which was written before these principles were fully understood, virtually all pool usage in Subversion follows the above guidelines.
One such legacy pattern is a tendency to allocate an object inside a pool, store the pool in the object, and then free that pool (either directly or through a close_foo() function) to destroy the object.
For example:
/*** Example of how NOT to use pools. Don't be like this. ***/
static foo_t *
make_foo_object(arg1, arg2, apr_pool_t *pool)
{
apr_pool_t *subpool = svn_pool_create(pool);
foo_t *foo = apr_palloc(subpool, sizeof(*foo));
foo->field1 = arg1;
foo->field2 = arg2;
foo->pool = subpool;
}
[...]
[Now some function calls make_foo_object() and returns, passing
back a new foo object.]
[...]
[Now someone, at some random call level, decides that the foo's
lifetime is over, and calls svn_pool_destroy(foo->pool).]
This is tempting, but it defeats the point of using pools, which is to not worry so much about individual allocations, but rather about overall performance and lifetime groups. Instead, foo_t generally should not have a `pool' field. Just allocate as many foo objects as you need in the current pool — when that pool gets cleared or destroyed, they will all go away simultaneously.
See also the Exception handling section, for details of how resources associated with a pool are cleaned up when that pool is destroyed.
In summary:
Objects should not have their own pools. An object is allocated into a pool defined by the constructor's caller. The caller knows the lifetime of the object and will manage it via the pool.
Functions should not create/destroy pools for their operation; they should use a pool provided by the caller. Again, the caller knows more about how the function will be used, how often, how many times, etc. thus, it should be in charge of the function's memory usage.
For example, think of a function that is being called multiple times in a tight loop. The caller clears the scratch pool on each iteration. Thus, the creation of an internal subpool is unnecessary and could be a significant overhead; instead, the function should just use the passed-in pool.
Whenever an unbounded iteration occurs, an iteration subpool should be used.
Given all of the above, it is pretty well mandatory to pass a pool to every function. Since objects are not recording pools for themselves, and the caller is always supposed to be managing memory, then each function needs a pool, rather than relying on some hidden magic pool. In limited cases, objects may record the pool used for their construction so that they can construct sub-parts, but these cases should be examined carefully.
See also Tracking down memory leaks for tips on diagnosing pool usage problems.
Always check for APR status codes (except APR_SUCCESS) with the APR_STATUS_IS_...() macros, not by direct comparison. This is required for portability to non-Unix platforms.
OK, here's how to use exceptions in Subversion.
Exceptions are stored in svn_error_t structures:
typedef struct svn_error_t
{
apr_status_t apr_err; /* APR error value, possibly SVN_ custom err */
const char *message; /* details from producer of error */
struct svn_error_t *child; /* ptr to the error we "wrap" */
apr_pool_t *pool; /* place to generate message strings from */
const char *file; /* Only used iff SVN_DEBUG */
long line; /* Only used iff SVN_DEBUG */
} svn_error_t;
If you are the original creator of an error, you would do something like this:
return svn_error_create(SVN_ERR_FOO, NULL,
"User not permitted to write file");
NOTICE the NULL field... indicating that this error has no child, i.e. it is the bottom-most error.
See also the section on writing error messages.
Subversion internally uses UTF-8 to store its data. This also applies to the 'message' string. APR is assumed to return its data in the current locale, so any text returned by APR needs conversion to UTF-8 before inclusion in the message string.
If you receive an error, you have three choices:
Handle the error yourself. Use either your own code, or just call the primitive svn_handle_error(err). (This routine unwinds the error stack and prints out messages converting them from UTF-8 to the current locale.)
When your routine receives an error which it intends to ignore or handle itself, be sure to clean it up using svn_error_clear(). Any time such an error is not cleared constitutes a memory leak.
A function that returns an error is not required to initialize its output parameters.
Throw the error upwards, unmodified:
error = some_routine(foo);
if (error)
return svn_error_trace(error);
Actually, a better way to do this would be with the SVN_ERR() macro, which does the same thing:
SVN_ERR(some_routine(foo));
Throw the error upwards, wrapping it in a new error structure by including it as the "child" argument:
error = some_routine(foo);
if (error)
{
svn_error_t *wrapper = svn_error_create(SVN_ERR_FOO, error,
"Authorization failed");
return wrapper;
}
Of course, there's a convenience routine which creates a wrapper error with the same fields as the child, except for your custom message:
error = some_routine(foo);
if (error)
{
return svn_error_quick_wrap(error,
"Authorization failed");
}
The same can (and should) be done by using the SVN_ERR_W() macro:
SVN_ERR_W(some_routine(foo), "Authorization failed");
In cases (b) and (c) it is important to know that resources allocated by your routine which are associated with a pool, are automatically cleaned up when the pool is destroyed. This means that there is no need to cleanup these resources before passing the error. There is therefore no reason not to use the SVN_ERR() and SVN_ERR_W() macros. Resources associated with pools are:
Memory
Files
All files opened with apr_file_open are closed at pool cleanup. Subversion uses this function in its svn_io_file_* api, which means that files opened with svn_io_file_* or apr_file_open will be closed at pool cleanup.
Some files (lock files for example) need to be removed when an operation is finished. APR has the APR_DELONCLOSE flag for this purpose. The following functions create files which are removed on pool cleanup:
apr_file_open and svn_io_file_open (when passed the APR_DELONCLOSE flag)
svn_io_open_unique_file (when passed TRUE in its delete_on_close)
Locked files are unlocked if they were locked using svn_io_file_lock.
The SVN_ERR() macro will create a wrapped error when
SVN_ERR__TRACING is defined. This helps developers
determine what caused the error, and can be enabled with the
--enable-maintainer-mode option to configure.
Sometimes, you just want to return whatever a called function returns, usually at the end of your own function. Avoid the temptation to directly return the result:
/* Don't do this! */
return some_routine(foo);
Instead, use the svn_error_trace meta-function to return the value. This ensures that stack tracing happens correctly when enabled.
return svn_error_trace(some_routine(foo));
Just like almost any other programming language, C has undesirable features which enables an attacker to make your program fail in predictable ways, often to the attacker's benefit. The goal of these guidelines is to make you aware of the pitfalls of C as they apply to the Subversion project. You are encouraged to keep these pitfalls in mind when reviewing code of your peers, as even the most skilled and paranoid programmers make occasional mistakes.
Input validation is the act of defining legal input and rejecting everything else. The code must perform input validation on all untrusted input.
Security boundaries:
A security boundary in the Subversion server code must be identified as such as this enables auditors to quickly determine the quality of the boundary. Security boundaries exist where the running code has access to information the user does not or where the code runs with privileges above those of the user making the request. Typical examples of such is code that does access control or an application with the SUID bit set.
Functions which make calls to a security boundary must include validation checks of the arguments passed. Functions which themselves are security boundaries should audit the input received and alarm when invoked with improper values.
[### todo: need some examples from Subversion here...]
String operations:
Use the string functions provided in apr_strings.h instead of standard C library functions that write to strings. The APR functions are safer because they do bounds-checking and dest allocation automatically. Although there may be circumstances where it's theoretically safe to use plain C string functions (such as when you already know the lengths of the source and dest), please use the APR functions anyway, so the code is less brittle and more reviewable.
Password storage:
Help users keep their passwords secret: When the client reads or writes password locally, it should ensure that the file is mode 0600. If the file is readable by other users, the client should exit with a message that tells the user to change the filemode due to the risk of exposure.
Some resources need destruction to ensure correct functioning of the application. Such resources include files, especially since open files cannot be deleted on Windows.
When writing an API which creates and returns a stream, in the background this stream may be stacked on a file or other stream. To ensure correct destruction of the resources the stream is built upon, it must correctly call the destructors of the stream(s) it is built upon (owns).
At first in https://svn.haxx.se/dev/archive-2005-12/0487.shtml and later in https://svn.haxx.se/dev/archive-2005-12/0633.shtml this was discussed in more general terms for files, streams, editors and window handlers.
As Greg Hudson put it:
On consideration, here is where I would like us to be:
- Streams which read from or write to an underlying object own that object, i.e. closing the stream closes the underlying object, if applicable.
- The layer (function or data type) which created a stream is responsible for closing it, except when the above rule applies.
- Window handlers are thought of as an odd kind of stream, and passing the final NULL window is considered closing the stream.
If you think of apply_textdelta as creating a window handler, then I don't think we're too far off. svn_stream_from_aprfile isn't owning its subsidiary file, svn_txdelta_apply is erroneously taking responsibility for closing the window stream it is passed, and there may be some other deviations.
There is one exception to the rules above though. When a stream is passed to a function as an argument (for example: the 'out' parameter of svn_client_cat2()), that routine can't call the streams destructor, since it did not create that resource.
If svn_client_cat2() creates a stream, it must also call the destructor for that stream. By the above model, that stream will call the destructor for the 'out' parameter. This is however wrong, because the responsibility to destruct the 'out' parameter lies elsewhere.
To solve this problem, at least in the stream case, svn_stream_disown() has been introduced. This function wraps a stream, making sure it's not destroyed, even though any streams stacked upon it may try to do so.
When you call a function that accepts a variable number of arguments and expects the list to be terminated with a null pointer constant (an example of such a function is apr_pstrcat), do not use the NULL symbol to terminate the list. Depending on compiler and platform, NULL may or may not be a pointer-sized constant; if it isn't the function may end up reading data beyond the end of the argument list.
Instead, use SVN_VA_NULL (defined since 1.9 in svn_types.h), which is guaranteed to be a null pointer constant. For example:
return apr_pstrcat(cmd->temp_pool, "Cannot parse expression '",
arg2, "' in SVNPath: ", expr_err, SVN_VA_NULL);
In addition to the GNU standards, Subversion uses these conventions:
When using a path or file name as input to most Subversion APIs, be sure to convert them to Subversion's internal/canonical form using the svn_dirent_internal_style() API. Alternately, when receiving a path or file name as output from a Subversion API, convert them into the expected form for your platform using the svn_dirent_local_style() API.
Use only spaces for indenting code, never tabs. Tab display width is not standardized enough, and anyway it's easier to manually adjust indentation that uses spaces.
Restrict lines to 79 columns, so that code will display well in a minimal standard display window. (There can be exceptions, such as when declaring a block of 80-column text with a few extra columns taken up by indentation, quotes, etc., if splitting each line in two would be unreasonably messy.)
All published functions, variables, and structures must be signified with the corresponding library name - such as libsvn_wc's svn_wc_adm_open. All library-internal declarations made in a library-private header file (such as libsvn_wc/wc.h) must be signified by two underscores after the library prefix (such as svn_wc__ensure_directory). All declarations private to a single file (such as the static function get_entry_url inside of libsvn_wc/update_editor.c) do not require any additional namespace decorations. Symbols that need to be used outside a library, but still are not public are put in a shared header file in the include/private/ directory, and use the double underscore notation. Such symbols may be used by Subversion core code only.
To recap:
/* Part of published API: subversion/include/svn_wc.h */
svn_wc_adm_open()
#define SVN_WC_ADM_DIR_NAME ...
typedef enum svn_wc_schedule_t ...
/* For use within one library only: subversion/libsvn_wc/wc.h */
svn_wc__ensure_directory()
#define SVN_WC__BASE_EXT ...
typedef struct svn_wc__compat_notify_baton_t ...
/* For use within one file: subversion/libsvn_wc/update_editor.c */
get_entry_url()
struct handler_baton {
/* For internal use in svn core code only:
subversion/include/private/svn_wc_private.h */
svn_wc__entry_versioned()
Pre-Subversion 1.5, private symbols which needed to be used outside of a library were put into public header files, using the double underscore notation. This practice has been abandoned, and any such symbols are legacy, maintained for backwards compatibility.
In text strings that might be printed out (or otherwise made available) to users, use only forward quotes around paths and other quotable things. For example:
$ svn revert foo
svn: warning: svn_wc_is_wc_root: 'foo' is not a versioned resource
$
There used to be a lot of strings that used a backtick for the first quote (`foo' instead of 'foo'), but that looked bad in some fonts, and also messed up some people's auto-highlighting, so we settled on the convention of always using forward quotes.
If you use Emacs, put something like this in your .emacs file, so you get svn-dev.el and svnbook.el when needed:
;;; Begin Subversion development section
(defun my-find-file-hook ()
(let ((svn-tree-path (expand-file-name "~/projects/subversion"))
(book-tree-path (expand-file-name "~/projects/svnbook")))
(cond
((string-match svn-tree-path buffer-file-name)
(load (concat svn-tree-path "/tools/dev/svn-dev")))
((string-match book-tree-path buffer-file-name)
;; Handle load exception for svnbook.el, because it tries to
;; load psgml, and not everyone has that available.
(condition-case nil
(load (concat book-tree-path "/src/tools/svnbook"))
(error
(message "(Ignored problem loading svnbook.el.)")))))))
(add-hook 'find-file-hooks 'my-find-file-hook)
;;; End Subversion development section
You'll need to customize the path for your setup, of course. You can also make the regexp to string-match more selective; for example, one developer says:
> Here's the regexp I'm using:
>
> "src/svn/[^/]*/\\(subversion\\|tools\\|build\\)/"
>
> Two things to notice there: (1) I sometimes have several
> working copies checked out under ...src/svn, and I want the
> regexp to match all of them; (2) I want the hook to catch only
> in "our" directories within the working copy, so I match
> "subversion", "tools" and "build" explicitly; I don't want to
> use GNU style in the APR that's checked out into my repo. :-)
We have a tradition of not marking files with the names of individual authors (i.e., we don't put lines like "Author: foo" or "@author foo" in a special position at the top of a source file). This is to discourage territoriality — even when a file has only one author, we want to make sure others feel free to make changes. People might be unnecessarily hesitant if someone appears to have staked a personal claim to the file.
Put two spaces between the end of one sentence and the start of the next. This helps readability, and allows people to use their editors' sentence-motion and -manipulation commands.
There are many other unspoken conventions maintained throughout the code, that are only noticed when someone unintentionally fails to follow them. Just try to have a sensitive eye for the way things are done, and when in doubt, ask.
Every commit needs a log message.
The intended audience for a log message is a developer who is already familiar with Subversion, but not necessarily familiar with this particular commit. Usually when someone goes back and reads a change, he no longer has in his head all the context around that change. This is true even if he is the author of the change! All the discussions and mailing list threads and everything else may be forgotten; the only clue to what the change is about comes from the log message and the diff itself. People revisit changes with surprising frequency, too: for example, it might be months after the original commit and now the change is being ported to a maintenance branch.
The log message is the introduction to the change.
If you are working on a branch, prefix your log message with:
On the 'name-of-branch' branch: (Start of your log message)
Start your log message with one line indicating the general nature of the change, and follow that with a descriptive paragraph if necessary.
This helps put developers in the right frame of mind for reading the rest of the log message.
If the commit is just one simple change to one file, then you can dispense with the general description and simply go straight to the detailed description, in the standard filename-then-symbol format shown below.
Throughout the log message, use full sentences, not sentence fragments. Fragments are more often ambiguous, and it takes only a few more seconds to write out what you mean. Certain fragments like "Doc fix", "New file", or "New function" are acceptable because they are standard idioms, and all further details should appear in the source code.
The log message should name every affected function, variable, macro, makefile target, grammar rule, etc, including the names of symbols that are being removed in this commit. This helps people searching through the logs later. Don't hide names in wildcards, because the globbed portion may be what someone searches for later. For example, this is bad:
* subversion/libsvn_ra_pigeons/twirl.c
(twirling_baton_*): Removed these obsolete structures.
(handle_parser_warning): Pass data directly to callees, instead
of storing in twirling_baton_*.
* subversion/libsvn_ra_pigeons/twirl.h: Fix indentation.
Later on, when someone is trying to figure out what happened to `twirling_baton_fast', they may not find it if they just search for "_fast". A better entry would be:
* subversion/libsvn_ra_pigeons/twirl.c
(twirling_baton_fast, twirling_baton_slow): Removed these
obsolete structures.
(handle_parser_warning): Pass data directly to callees, instead
of storing in twirling_baton_*.
* subversion/libsvn_ra_pigeons/twirl.h: Fix indentation.
The wildcard is okay in the description for `handle_parser_warning', but only because the two structures were mentioned by full name elsewhere in the log entry.
You should also include property changes in your log messages. For example, if you were to modify the "svn:ignore" property on the trunk, you might put something like this in your log:
* trunk/ (svn:ignore): Ignore 'build'.
The above only applies to properties you maintain, not those maintained by subversion like "svn:mergeinfo".
Note how each file gets its own entry prefixed with an "*", and the changes within a file are grouped by symbol, with the symbols listed in parentheses followed by a colon, followed by text describing the change. Please adhere to this format, even when only one file is changed — not only does consistency aid readability, it also allows software to colorize log entries automatically.
As an exception to the above, if you make exactly the same change in several files, list all the changed files in one entry. For example:
* subversion/libsvn_ra_pigeons/twirl.c,
subversion/libsvn_ra_pigeons/roost.c:
Include svn_private_config.h.
If all the changed files are deep inside the source tree, you can shorten the file name entries by noting the common prefix before the change entries:
[in subversion/bindings/swig/birdsong]
* dialects/nightingale.c (get_base_pitch): Allow 3/4-tone
pitch variation to account for trait variability amongst
isolated populations Erithacus megarhynchos.
* dialects/gallus_domesticus.c: Remove. Unreliable due to
extremely low brain-to-body mass ratio.
If your change is related to a specific issue in the issue tracker, then include a string like "issue #N" in the log message, but make sure you still summarize what the change is about. For example, if a patch resolves issue #1729, then the log message might be:
Fix issue #1729: Don't crash because of a missing file.
* subversion/libsvn_ra_ansible/get_editor.c
(frobnicate_file): Check that file exists before frobnicating.
Try to put related changes together. For example, if you create svn_ra_get_ansible2(), deprecating svn_ra_get_ansible(), then those two things should be near each other in the log message:
* subversion/include/svn_ra.h
(svn_ra_get_ansible2): New prototype, obsoletes svn_ra_get_ansible.
(svn_ra_get_ansible): Deprecate.
For large changes or change groups, group the log entry into paragraphs separated by blank lines. Each paragraph should be a set of changes that accomplishes a single goal, and each group should start with a sentence or two summarizing the change. Truly independent changes should be made in separate commits, of course.
See Crediting for how to give credit to someone else if you are committing their patch, or committing a change they suggested.
One should never need the log entries to understand the current code. If you find yourself writing a significant explanation in the log, you should consider carefully whether your text doesn't actually belong in a comment, alongside the code it explains. Here's an example of doing it right:
(consume_count): If `count' is unreasonable, return 0 and don't
advance input pointer.
And then, in `consume_count' in `cplus-dem.c':
while (isdigit((unsigned char)**type))
{
count *= 10;
count += **type - '0';
/* A sanity check. Otherwise a symbol like
`_Utf390_1__1_9223372036854775807__9223372036854775'
can cause this function to return a negative value.
In this case we just consume until the end of the string. */
if (count > strlen(*type))
{
*type = save;
return 0;
}
This is why a new function, for example, needs only a log entry saying "New Function" --- all the details should be in the source.
You can make common-sense exceptions to the need to name everything that was changed. For example, if you have made a change which requires trivial changes throughout the rest of the program (e.g., renaming a variable), you needn't name all the functions affected, you can just say "All callers changed". When renaming any symbol, please remember to mention both the old and new names, for traceability; see r861020 for an example.
In general, there is a tension between making entries easy to find by searching for identifiers, and wasting time or producing unreadable entries by being exhaustive. Use the above guidelines and your best judgment, and be considerate of your fellow developers. (Also, use "svn log" to see how others have been writing their log entries.)
Log messages for documentation or translation have somewhat looser guidelines. The requirement to name every symbol obviously does not apply, and if the change is just one more increment in a continuous process such as translation, it's not even necessary to name every file. Just briefly summarize the change, for example: "More work on Malagasy translation." Please write your log messages in English, so everybody involved in the project can understand the changes you made.
If you're using a branch to "checkpoint" your code, and don't feel it's ready for review, please put some sort of notice at the top of the log message, after the 'On the 'xxx' branch notice', such as:
*** checkpoint commit -- please don't waste your time reviewing it ***
And if a later commit on that branch should be reviewed, then please supply, in the log message, the appropriate 'svn diff' command, since the diff would likely involve two non-adjacent commits on that branch, and reviewers shouldn't have to spend time figuring out which ones they are.
It is very important to record code contributions in a consistent and parseable way. This allows us to write scripts to figure out who has been actively contributing — and what they have contributed — so we can spot potential new committers quickly. The Subversion project uses human-readable but machine-parseable fields in log messages to accomplish this.
When committing a patch written by someone else, use "Patch by: " at the beginning of a line to indicate the author:
Fix issue #1729: Don't crash because of a missing file.
* subversion/libsvn_ra_ansible/get_editor.c
(frobnicate_file): Check that file exists before frobnicating.
Patch by: J. Random <jrandom@example.com>
If multiple individuals wrote the patch, list them each on a separate line — making sure to start each continuation line with whitespace. Non-committers should be listed by name, if known, and e-mail. Full and partial committers should be listed by their canonical usernames from COMMITTERS (the leftmost column in that file). Additionally, "me" is an acceptable shorthand for the person actually committing the change.
Fix issue #1729: Don't crash because of a missing file.
* subversion/libsvn_ra_ansible/get_editor.c
(frobnicate_file): Check that file exists before frobnicating.
Patch by: J. Random <jrandom@example.com>
Enrico Caruso <codingtenor@codingtenor.com>
jcommitter
me
If someone found the bug or pointed out the problem, but didn't write the patch, indicate their contribution with "Found by: " (or "Reported by: "):
Fix issue #1729: Don't crash because of a missing file.
* subversion/libsvn_ra_ansible/get_editor.c
(frobnicate_file): Check that file exists before frobnicating.
Found by: J. Random <jrandom@example.com>
If someone suggested something useful, but didn't write the patch, indicate their contribution with "Suggested by: ":
Extend the Contribulyzer syntax to distinguish finds from ideas. * www/hacking.html (crediting): Adjust accordingly. Suggested by: dlr
If someone test-drove a patch, use "Tested by: ":
Fix issue #23: random crashes on FreeBSD 3.14.
Tested by: Old Platformer
(I couldn't reproduce the problem, but Old hasn't seen any crashes since
he applied the patch.)
* subversion/libsvn_fs_sieve/obliterate.c
(cover_up): Account for sieve(2) returning 6.
If someone reviewed the change, use "Review by: " (or "Reviewed by: " if you prefer):
Fix issue #1729: Don't crash because of a missing file.
* subversion/libsvn_ra_ansible/get_editor.c
(frobnicate_file): Check that file exists before frobnicating.
Review by: Eagle Eyes <eeyes@example.com>
A field may have multiple lines, and a log message may contain any combination of fields:
Fix issue #1729: Don't crash because of a missing file.
* subversion/libsvn_ra_ansible/get_editor.c
(frobnicate_file): Check that file exists before frobnicating.
Patch by: J. Random <jrandom@example.com>
Enrico Caruso <codingtenor@codingtenor.com>
me
Found by: J. Random <jrandom@example.com>
Review by: Eagle Eyes <eeyes@example.com>
jcommitter
Further details about a contribution should be listed in a parenthetical aside immediately after the corresponding field. Such an aside always applies to the field right above it; in the following example, the fields have been spaced out for readability, but note that the spacing is optional and not necessary for parseability:
Fix issue #1729: Don't crash because of a missing file.
* subversion/libsvn_ra_ansible/get_editor.c
(frobnicate_file): Check that file exists before frobnicating.
Patch by: J. Random <jrandom@example.com>
(Tweaked by me.)
Review by: Eagle Eyes <eeyes@example.com>
jcommitter
(Eagle Eyes caught an off-by-one-error in the basename extraction.)
Currently, these fields
Patch by: Suggested by: Found by: Review by: Tested by:
are the only officially-supported crediting fields (where "supported" means scripts know to look for them), and they are widely used in Subversion log messages. Future fields will probably be of the form "VERB by: ", and from time to time someone may use a field that sounds official but really is not — for example, there are a few instances of "Inspired by: ". These are okay, but try to use an official field, or a parenthetical aside, in preference to creating your own. Also, don't use "Reported by: " when the reporter is already recorded in an issue; instead, simply refer to the issue.
Look over Subversion's existing log messages to see how to use these fields in practice. This command from the top of your trunk working copy will help:
svn log | contrib/client-side/search-svnlog.pl "(Patch|Review|Suggested) by: "
Note: The "Approved by: " field seen in some commit messages is totally unrelated to these crediting fields, and is generally not parsed by scripts. It is simply the standard syntax for indicating either who approved a partial committer's commit outside their usual area, or (in the case of merges to release branches) who voted for the change to be merged.
The Subversion repository is mirrored to GitHub at https://github.com/apache/subversion/.
Some users might create pull requests in GitHub. If the code is committed to the Subversion repository, make sure to include text in the log message to automatically close the pull request:
This fixes #NNN in GitHub
To manage pull requests without committing code, you must have a GitHub account connected to your ASF id and you must have the triager role assigned to your account by ASF Infra.
Greg Stein wrote a custom build system for Subversion, which had been using `automake' and recursive Makefiles. Now it uses a single, top-level Makefile, generated from Makefile.in (which is kept under revision control). `Makefile.in' in turn includes `build-outputs.mk', which is automatically generated from `build.conf' by the `gen-make.py' script. Thus, the latter two are under revision control, but `build-outputs.mk' is not.
Here is Greg's original mail describing the system, followed by some advice about hacking it:
From: Greg Stein <gstein@lyra.org>
Subject: new build system (was: Re: CVS update: MODIFIED: ac-helpers ...)
To: dev@subversion.tigris.org
Date: Thu, 24 May 2001 07:20:55 -0700
Message-ID: <20010524072055.F5402@lyra.org>
On Thu, May 24, 2001 at 01:40:17PM -0000, gstein@tigris.org wrote:
> User: gstein
> Date: 01/05/24 06:40:17
>
> Modified: ac-helpers .cvsignore svn-apache.m4
> Added: . Makefile.in
> Log:
> Switch over to the new non-recursive build system.
>...
Okay... this is it. We're now on the build system.
"It works on my machine."
I suspect there may be some tweaks to make on different OSs. I'd be
interested to hear if Ben can really build with normal BSD make. It
should be possible.
The code supports building, installation, checking, and
dependencies. It does *NOT* yet deal with the doc/ subdirectory. That
is next; I figured this could be rolled out and get the kinks worked
out while I do the doc/ stuff. Oh, it doesn't build Neon or APR yet
either. I also saw a problem where libsvn_fs wasn't getting built
before linking one of the test proggies (see below).
Basic operation: same as before.
$ ./autogen.sh
$ ./configure OPTIONS
$ make
$ make check
$ make install
There are some "make check" scripts that need to be fixed up. That'll
happen RSN. Some of them create their own log, rather than spewing to
stdout (where the top-level make will place the output into
[TOP]/tests.log).
The old Makefile.am files are still around, but I'll be tossing those
along with a bunch of tweaks to all the .cvsignore files. There are a
few other cleanups, too. But that can happen as a step two.
[ $ cvs rm -f `find . -name Makefile.rm`
See the mistake in that line? I didn't when I typed it. The find
returned nothing, so cvs rm -f proceeded to delete my entire
tree. And the -f made sure to delete all my source files, too. Good
fugging thing that I had my mods in some Emacs buffers, or I'd be
bitching.
I am *so* glad that Ben coded SVN to *not* delete locally modified
files *and* that we have an "undel" command. I had to go and tweak a
bazillion Entries files to undo the delete...
]
The top-level make has a number of shortcuts in it (well, actually in
build-outputs.mk):
$ make subversion/libsvn_fs/libsvn_fs.la
or
$ make libsvn_fs
The two are the same. So... when your test proggie fails to link
because libsvn_fs isn't around, just run "make libsvn_fs" to build it
immediately, then go back to the regular "make".
Note that the system still conditionally builds the FS stuff based
on whether DB (See 'Building on Unix' below) is available, and
mod_dav_svn if Apache is available.
Handy hint: if you don't like dependencies, then you can do:
$ ./autogen.sh -s
That will skip the dependency generation that goes into
build-outputs.mk. It makes the script run quite a bit faster (48 secs
vs 2 secs on my poor little Pentium 120).
Note that if you change build.conf, you can simply run:
$ ./gen-make.py build.conf
to regen build-outputs.mk. You don't have to go back through the whole
autogen.sh / configure process.
You should also note that autogen.sh and configure run much faster now
that we don't have the automake crap. Oh, and our makefiles never
re-run configure on you out of the blue (gawd, I hated when automake
did that to me).
Obviously, there are going to be some tweaky things going on. I also
think that the "shadow" builds or whatever they're called (different
source and build dirs) are totally broken. Something tweaky will have
to happen there. But, thankfully, we only have one Makefile to deal
with.
Note that I arrange things so that we have one generated file
(build-outputs.mk), and one autoconf-generated file (Makefile from
.in). I also tried to shove as much logic/rules into
Makefile.in. Keeping build-outputs.mk devoid of rules (thus, implying
gen-make.py devoid of rules in its output generation) manes that
tweaking rules in Makefile.in is much more approachable to people.
I think that is about it. Send problems to the dev@ list and/or feel
free to dig in and fix them yourself. My next steps are mostly
cleanup. After that, I'm going to toss out our use of libtool and rely
on APR's libtool setup (no need for us to replicate what APR already
did).
Cheers,
-g
--
Greg Stein, http://www.lyra.org/
And here is some advice for those changing or testing the configuration/build system:
From: Karl Fogel <kfogel@collab.net>
To: dev@subversion.tigris.org
Subject: when changing build/config stuff, always do this first
Date: Wed 28 Nov 2001
Yo everyone: if you change part of the configuration/build system,
please make sure to clean out any old installed Subversion libs
*before* you try building with your changes. If you don't do this,
your changes may appear to work fine, when in fact they would fail if
run on a truly pristine system.
This script demonstrates what I mean by "clean out". This is
`/usr/local/cleanup.sh' on my system. It cleans out the Subversion
libs (and the installed httpd-2.0 libs, since I'm often reinstalling
that too):
#!/bin/sh
# Take care of libs
cd /usr/local/lib || exit 1
rm -f APRVARS
rm -f libapr*
rm -f libexpat*
rm -f libneon*
rm -f libsvn*
# Take care of headers
cd /usr/local/include || exit 1
rm -f apr*
rm -f svn*
rm -f neon/*
# Take care of headers
cd /usr/local/apache2/lib || exit 1
rm -f *
When someone reports a configuration bug and you're trying to
reproduce it, run this first. :-)
The voice of experience,
-Karl
The build system is a vital tool for all developers working on trunk. Sometimes, changes made to the build system work perfectly fine for one developer, but inadvertently break the build system for another.
To prevent loss of productivity, any committer (full or partial) can immediately revert any build system change that breaks their ability to effectively do development on their platform of choice, as a matter of ordinary routing, without fear of accusations of an over-reaction. The log message of the commit reverting the change should contain an explanatory note saying why the change is being reverted, containing sufficient detail to be suitable to start off a discussion of the problem on dev@, should someone chose to reply to the commit mail.
However, care should be taken not go into "default revert mode". If you can quickly fix the problem, then please do so. If not, then stop and think about it for a minute. After you've thought about it, and you still have no solution, go ahead and revert the change, and bring the discussion to the list.
Once the change has been reverted, it is up to the original committer of the reverted change to either recommit a fixed version of their original change, if, based on the reverting committer's rationale, they feel very certain that their new version definitely is fixed, or, to submit the revised version for testing to the reverting committer before committing it again.
For a description of how to use and add tests to Subversion's automated test framework, please read subversion/tests/README and subversion/tests/cmdline/README.
The ASF Infrastructure team manages a BuildBot build/test farm. The Buildbot waterfall for the Subversion project is located here:
For more information about build services, head over to ci2.apache.org.
If you'd like to receive notifications about buildbot build and test failures, please subscribe to the notifications@ mailing list.
Buildbot is configured in the Infra repository, specifically, the subversion.py file.
From: Karl Fogel <kfogel@collab.net> Subject: writing test cases To: dev@subversion.tigris.org Date: Mon, 5 Mar 2001 15:58:46 -0600 Many of us implementing the filesystem interface have now gotten into the habit of writing the test cases (see fs-test.c) *before* writing the actual code. It's really helping us out a lot -- for one thing, it forces one to define the task precisely in advance, and also it speedily reveals the bugs in one's first try (and second, and third...). I'd like to recommend this practice to everyone. If you're implementing an interface, or adding an entirely new feature, or even just fixing a bug, a test for it is a good idea. And if you're going to write the test anyway, you might as well write it first. :-) Yoshiki Hayashi's been sending test cases with all his patches lately, which is what inspired me to write this mail to encourage everyone to do the same. Having those test cases makes patches easier to examine, because they show the patch's purpose very clearly. It's like having a second log message, one whose accuracy is verified at run-time. That said, I don't think we want a rigid policy about this, at least not yet. If you encounter a bug somewhere in the code, but you only have time to write a patch with no test case, that's okay -- having the patch is still useful; someone else can write the test case. As Subversion gets more complex, though, the automated test suite gets more crucial, so let's all get in the habit of using it early. -K
The SVN_DBG debugging tool is a C Preprocessor macro that sends debugging output to stdout (by default) or stderr whilst not interfering with the SVN test suite.
It provides an alternative to a debugger such as gdb, or alternatively, extra information to assist in the use of a debugger. It might be especially useful in situations where a debugger cannot be used.
The svn_debug module contains two debug aid macros that print the
file:line of the call and printf-like arguments to
the #SVN_DBG_OUTPUT stdio stream (#stdout by
default):
SVN_DBG( ( const char *fmt, ...) ) /* double braces are neccessary */and
SVN_DBG_PROPS( ( apr_hash_t *props, const char *header_fmt, ...) )
Controlling SVN_DBG output:
--enable-maintainer-mode.
SVN_DBG_QUIET
variable to 1 in your shell environment.
SVN_DBG and SVN_DBG_PROPS macros from
any code you are committing and from any patch that you send to the
list. (AKA: Do not forget a scalpel in the patient!)
The SVN_DBG macro definitions and code are located in:
Sample patch showing usage of the SVN_DBG macro:
Index: subversion/libsvn_fs_fs/fs_fs.c
===================================================================
--- subversion/libsvn_fs_fs/fs_fs.c (revision 1476635)
+++ subversion/libsvn_fs_fs/fs_fs.c (working copy)
@@ -2303,6 +2303,9 @@ get_node_revision_body(node_revision_t **noderev_p
/* First, try a cache lookup. If that succeeds, we are done here. */
SVN_ERR(get_cached_node_revision_body(noderev_p, fs, id, &is_cached, pool));
+ SVN_DBG(("Getting %s from: %s\n",
+ svn_fs_fs__id_unparse(id),
+ is_cached ? "cache" : "disk"));
if (is_cached)
return SVN_NO_ERROR;
Sample patch showing usage of the SVN_DBG_PROPS macro:
Index: subversion/svn/proplist-cmd.c
===================================================================
--- subversion/svn/proplist-cmd.c (revision 1475745)
+++ subversion/svn/proplist-cmd.c (working copy)
@@ -221,6 +221,7 @@ svn_cl__proplist(apr_getopt_t *os,
URL, &(opt_state->start_revision),
&rev, ctx, scratch_pool));
+ /* this can be called with svn proplist --revprop -r <rev> */
+ SVN_DBG_PROPS((proplist,"The variable apr_hash_t *proplist contains: "));
if (opt_state->xml)
{
svn_stringbuf_t *sb = NULL;
'mod_dav_svn.so' contains the main Subversion server logic; it runs as a module within mod_dav, which runs as a module within httpd. If httpd is probably using dynamic shared modules, you might need to set breakpoint pending on (in ~/.gdbinit) before setting breakpoints in mod_dav_svn would be possible. Alternatively, you may start httpd, interrupt it, set your breakpoint, and continue:
% gdb httpd (gdb) run -X ^C (gdb) break some_func_in_mod_dav_svn (gdb) continue
The -X switch is equivalent to -DONE_PROCESS and -DNO_DETACH, which ensure that httpd runs as a single thread and remains attached to the tty, respectively. As soon as it starts, it sits and waits for requests; that's when you hit control-C and set your breakpoint.
You'll probably want to watch Apache's run-time logs
/usr/local/apache2/logs/error_log /usr/local/apache2/logs/access_log
to help determine what might be going wrong and where to set breakpoints.
Alternatively, running ./subversion/tests/cmdline/davautocheck.sh --gdb in a working copy will start httpd using the mod_dav_svn in that working copy. You can then run individual Python tests against that: ./basic_tests.py --url=http://localhost:3691/.
Bugs in ra_svn usually manifest themselves with one of the following cryptic error messages:
svn: Malformed network data svn: Connection closed unexpectedly
(The first message can also mean the data stream was corrupted in tunnel mode by user dotfiles or hook scripts; see issue #1145.) The first message generally means you to have to debug the client; the second message generally means you have to debug the server.
It is easiest to debug ra_svn using a build with --disable-shared --enable-maintainer-mode. With the latter option, the error message will tell you exactly what line to set a breakpoint at; otherwise, look up the line number at the end of marshal.c:vparse_tuple() where it returns the "Malformed network data" error.
To debug the client, simply pull it up in gdb, set a breakpoint, and run the offending command:
% gdb svn
(gdb) break marshal.c:NNN
(gdb) run ARGS
Breakpoint 1, vparse_tuple (list=___, pool=___, fmt=___,
ap=___) at subversion/libsvn_ra_svn/marshal.c:NNN
NNN "Malformed network data");
There are several bits of useful information:
A backtrace will tell you exactly what protocol exchange is failing.
"print *conn" will show you the connection buffer. read_buf, read_ptr, and read_end represent the read buffer, which can show you the data the marshaller is looking at. (Since read_buf isn't generally 0-terminated at read_end, be careful of falsely assuming that there's garbage data in the buffer.)
The format string determines what the marshaller was expecting to see.
To debug the server in daemon mode, pull it up in gdb, set a breakpoint (usually a "Connection closed unexpectedly" error on the client indicates a "Malformed network data" error on the server, although it can also indicate a core dump), and run it with the "-X" option to serve a single connection:
% gdb svnserve (gdb) break marshal.c:NNN (gdb) run -X
Then run the offending client command. From there, it's just like debugging the client.
Debugging the server in tunnel mode is more of a pain. You'll need to stick something like "{ int x = 1; while (x); }" near the top of svnserve's main() and put the resulting svnserve in the user path on the server. Then start an operation, gdb attach the process on the server, "set x = 0", and step through the code as desired.
Tracing the network traffic between the client and the server can be helpful in debugging. There are several ways to go about doing a network trace (and this list is not exhaustive).
You may well want to disable compression when doing a network trace — see the http-compression parameter in the servers configuration file.
Use Wireshark (formerly known as "Ethereal") to eavesdrop on the conversation.
First, make sure that between captures within the same wireshark session, you hit Clear, otherwise filters from one capture (say, an HTTP capture) might interfere with others (say, an ra_svn capture).
Assuming you're cleared, then:
Pull down the Capture menu, and choose Capture Filters.
If debugging the http:// (WebDAV) protocol, then in the window
that pops up, choose "HTTP TCP port (80)"
(which should result in the filter string
"tcp port http").
If debugging the svn:// (ra_svn) protocol, then choose New,
give the new filter a name (say, "ra_svn"), and type
"tcp port 3690" into the filter string box.
When done, click OK.
Again go to the Capture menu, this time choose Interfaces, and click Options next to the appropriate interface (probably you want interface "lo", for "loopback", assuming the server will run on the same machine as the client).
Turn off promiscuous mode by unchecking the appropriate checkbox.
Click the Start button in the lower right to start the capture.
Run your Subversion client.
Click the Stop icon (a red X over an ethernet interface card) when the operation is finished (or Capture->Stop should work). Now you have a capture. It looks like a huge list of lines.
Click on the Protocol column to sort.
Then, click on the first relevant line to select it; usually this is just the first line.
Right click, and choose Follow TCP Stream. You'll be presented with the request/response pairs of the Subversion client's HTTP conversion.
The above instructions are specific to the graphical version of Wireshark (version 0.99.6), and don't apply to the command-line version known as "tshark" (which corresponds to "tethereal", from back when Wireshark was called Ethereal).
Another alternative is to set up a logging proxy between the Subversion client and server. A simple way to do this is to use the socat program. For example, to log communication with an svnserve instance, run the following command:
socat -v TCP-LISTEN:9630,reuseaddr,fork TCP4:localhost:svn
Then run your svn commands using an URL base of svn://127.0.0.1:9630/; socat will forward the traffic from port 9630 to the normal svnserve port (3690), and will print all traffic in both directions to standard error, prefixing it with < and > signs to show the direction of the traffic.
To log readable HTTP from an encrypted https:// connection run a socat proxy that connects using TLS to the server:
socat -v TCP-LISTEN:9630,reuseaddr,fork OPENSSL:example.com:443
and then use that as a proxy for a plain http:// connection:
svn ls http://example.com/svn/repos/trunk \
--config-option servers:global:http-proxy-host=localhost \
--config-option servers:global:http-proxy-port=9630 \
--config-option servers:global:http-compression=no
The socat proxy logs the plain HTTP while all the network traffic with the server is encrypted using TLS.
If you're debugging a http client/server setup you can use a web debugging proxy like Charles or Fiddler.
Once you've setup such a proxy you'll need to configure Subversion to use the proxy. This can be done with the http-proxy-host and http-proxy-port parameters in the servers configuration file. You can also specify the proxy on the command line with these options --config-option 'servers:global:http-proxy-host=127.0.0.1' --config-option 'servers:global:http-proxy-port=8888'.
Our use of APR pools makes it unusual for us to have memory leaks in the strictest sense; all the memory we allocate will be cleaned up eventually. But sometimes an operation takes more memory than it should; for instance, a checkout of a large source tree should not use much more memory than a checkout of a small source tree. When that happens, it generally means we're allocating memory from a pool whose lifetime is too long.
If you have a favorite memory leak tracking tool, you can configure with --enable-pool-debug (which will make every pool allocation use its own malloc()), arrange to exit in the middle of the operation, and go to it. If not, here's another way:
Configure with --enable-pool-debug=verbose-alloc. Make sure to rebuild all of APR and Subversion so that every allocation gets file-and-line information.
Run the operation, piping stderr to a file. Hopefully you have lots of disk space.
In the file, you'll see lots of lines which look like:
POOL DEBUG: [5383/1024] PCALLOC ( 2763/ 2763/ 5419) \
0x08102D48 "subversion/svn/main.c:612" \
<subversion/libsvn_subr/auth.c:122> (118/118/0)
What you care about most is the tenth field (the one in quotes), which gives you the file and line number where the pool for this allocation was created. Go to that file and line and determine the lifetime of the pool. In the example above, main.c:612 indicates that this allocation was made in the top-level pool of the svn client. If this were an allocation which was repeated many times during the course of an operation, that would indicate a source of a memory leak. The eleventh field (the one in brackets) gives the file and line number of the allocation itself.
The Subversion project welcomes improvements to its web site. However, the process is not as simple as clicking "Save As" in a browser, editing and mailing the change. For one thing, many pages are actually composed of three or more files so browsers do not save a correctly rendered copy.
Because of this, if you're planning to submit substantial changes, we recommend that you obtain a copy of the sources and set up a testing mirror to check your changes.
Of course, for small changes, simply inspecting the patch visually will often be sufficient.
The source to the website is available from a Subversion repository. To browse the sources, go to https://svn.apache.org/repos/asf/subversion/site/
To download a copy to ~/projects/svn, which is the
location used for the rest of this page, use the following commands:
mkdir -p ~/projects/svn cd ~/projects/svn svn co https://svn.apache.org/repos/asf/subversion/site/ site
If you download to another location, you will need to adjust paths in your web server configuration to point there.
The Subversion web site uses Server Side Includes (SSI) to assemble pages within the web server. This means that to validate any changes you might wish to make, you need to view the relevant pages through a web browser connected to a server installed on your system, either Apache 2.2 or Apache 2.4.
The following steps should provide an Apache virtualhost
that correctly renders a local copy of the Subversion web site on
a Unix-type system. This is likely to be located under
/etc/apache2, /etc/httpd or a similiar directory,
depending on your system. These instructions have been tested on
Apache 2.2 and Apache 2.4.
/home/user/projects/svn/sitesite/publish
directory within the working copy mentioned above as DocumentRoot
for either the main server or a VirtualHost.mod_include.soOptions +Includes
AddOutputFilter INCLUDES .html
Putting it all together, an example VirtualHost configuration is:
<VirtualHost *:8080>
ServerAdmin webmaster@localhost
DocumentRoot /home/user/projects/svn/site/publish
<Directory /home/user/projects/svn/site/publish/>
Options +Includes
AddOutputFilter INCLUDES .html
</Directory>
ErrorLog ${APACHE_LOG_DIR}/error.log
# Possible values include: debug, info, notice, warn, error, crit,
# alert, emerg.
LogLevel debug
CustomLog ${APACHE_LOG_DIR}/access.log combined
</VirtualHost>
After restarting or reloading the server, you should see a copy of
the Subversion community guide Web Changes page if you use
the following link:
http://127.0.0.1:8080/docs/community-guide/(none)#web_mirror
Please validate all patches which make substantial changes to the web site.
If you have set up a mirror of the website as advised on this page, use the command line to fetch a correctly rendered copy of the page you've changed with
wget http://127.0.0.1:8080/docs/community-guide/YOUR_CHANGED_PAGE.html
then upload the resulting file to a HTML validator, for example, W3C validator service.
When writing log messages for patches regarding the project's web pages, eg:
https://subversion.apache.org/docs/community-guide/some_page.html#section-name
list the names of files modified in the patch in the log message,
relative to the site/ directory and list anchors of
sections added or modified like this:
* docs/community-guide/some_page.html (section-name): fixed issue xyz
For a full discussion of the Subversion patch requirements, please follow the project general patch guidelines and log message guidelines.
The advice below is based on years of experience with the Subversion mailing lists, and addresses the problems seen most frequently on those lists. It should not be taken as a complete guide to mailing list etiquette — you can find one of those on the Net pretty easily if you want one.
If you follow these conventions when posting to our mailing lists, your post is much more likely to be read and answered.
When in doubt, mail users@subversion.apache.org, not dev@subversion.apache.org. There are many experienced people (including some of Subversion's maintainers) on users@ list — they may be able to answer your question, or if you think you've found a bug they can determine whether or not it is a genuine bug. You should even post to users@ when you want to suggest a new feature: many feature suggestions are ideas that have been discussed before, and someone on the users@subversion.apache.org mailing list will usually be able to tell if that's the case with your suggestion.
Please do not post to dev@ as a last resort after failing to get an answer on users@. The two lists have different charters: users@ is a support forum, dev@ is a development discussion list. When a support question goes unanswered on users@, that is unfortunate, but it does not make the question appropriate for dev@.
Of course, if the mail is about a possible bug in Subversion, and got no reaction on users@, then asking on dev@ is fine — bugs are a development topic. And patches should always be sent directly to dev@.
Sometimes, when really impassioned about a topic, it's tempting to respond to every message in a mail thread. Please don't do this. Our mailing lists are already high-traffic, and following up to every message only adds to the noise.
Instead, read the entire mail thread, think carefully about what you have to say, pick a single message to reply to, and then lay out your thoughts. Occasionally it might make sense to reply to two separate messages in a thread, but only if the topics have started to diverge.
Please don't use lines longer than 72 columns. Many people use 80-column terminals to read their email. By writing your text in 72 columns, you leave room for quoting characters to be added in future replies without forcing a rewrapping of the text. The 72-column limit only applies to the prose part of your message, of course. If you're posting a patch, see the section on patches.
Some mailers do a kind of automatic line-wrapping, whereby when you're writing your mail, the display shows line breaks that aren't actually there. When the mail reaches the list, it won't have the line breaks you thought it had. If your mail editor does this, look for a setting you can tweak to make it show true line breaks.
Capitalize the first letter of each sentence, and use paragraphs. If you're showing screen output or some other sort of example, offset it so it's clearly separate from the prose. If you don't do these things, your mail will be much less readable than it could be, and many people will not bother to read it at all.
Make sure to use your mailreader's "Follow-up" or "Reply-to-all" or "Group reply" feature when responding to a list post. Otherwise, your mail will only go to the author of the original post, not to the whole list. Unless there's a reason to reply privately, it's always better to respond to the list, so everyone can watch and learn. (Also, many people who frequently get private responses to their posts have indicated that they would prefer those responses to go to the list instead.)
Note that the Subversion mailing lists do not modify the Reply-to header to redirect responses to the list. They leave Reply-to set to whatever the original sender had, for the reasons listed in https://www.unicom.com/pw/reply-to-harmful.html, in particular the "Principle of Least Damage" and "Can't Find My Way Back Home" sections. From time to time, someone posts asking why we don't set the Reply-to header. Sometimes that person will mention https://marc.merlins.org/netrants/reply-to-useful.html, which gives arguments in favor of modifying the Reply-to field. The list administrators are aware of both documents, and see that both sides of the argument have merits, but in the end have chosen not to modify the Reply-to headers. Please don't resurrect the topic.
Don't start a new thread (subject) by replying to an existing post. Instead, start a fresh mail, even if that means you have to write out the list address by hand. If you reply to an existing post, your mailreader may include metadata that marks your post as a followup in that thread. Changing the Subject header is not enough to prevent this! Many mailreaders will still preserve enough metadata to put your post in the wrong thread. If this happens, not only will some people not see your post (because they're ignoring that thread), but people who are reading the thread will waste their time with your off-topic post. The safest way to avoid this is to never use "reply" to start a new topic.
(The root of the problem is really that some mail interfaces do not indicate that the message generated by the "Reply" function is different from a fresh message. If you use such a program, consider submitting an enhancement request or a patch to its developers to make it show a distinction.)
If you do need to change the Subject header while preserving the thread (perhaps because the thread has wandered into some other topic), do it by making a post under the new subject with the old subject in parenthesis, like this:
Blue asparagus
|
|_ Re: Blue asparagus
|
|_ Yellow elephants (was: Re: Blue asparagus) <-- ### switch ###
|
|_ Re: Yellow elephants
Please don't reflexively chide people for top-posting. "Top-posting" is the practice of putting the response text above the quoted text, instead of interleaved with it or below it. Usually, the quoted text provides essential context for understanding the response, and so top-posting is a hindrance. Sometimes, people top-post when it would have been better to inter-post or bottom-post, and others chide them for this. If you must chide, do it gently, and certainly don't bother to make an extra post just to point out a minor problem like this. There are even situations where top-posting is preferable — for example, when the response is short and general, and applies to the entirety of a long passage of quoted text. So top-posting is always a judgement call, and in any case it's not a major inconvenience even when done inappropriately.
If you came here looking for advice on how to quote, instead of advice on how to not flame people for their bad quoting habits, see https://www.netmeister.org/news/learn2quote.html (Deutsch: http://www.afaik.de/usenet/faq/zitieren/download/zitieren-alles.html).
See here for advice on how to send in a patch. Note that you can send in a patch to modify these web pages as well as to modify code; the web pages' repository URL is https://svn.apache.org/repos/asf/subversion/site/.
Please use ASCII or ISO-8859 text if possible. Don't post HTML mails, RichText mails, or other formats that might be opaque to text-only mailreaders. Regarding language: we don't have an English-only policy, but you will probably get the best results by posting in English — it is the language shared by the greatest number of list participants.
Subversion isn't perfect software. It contains bugs, lacks features, and has room for improvement like any other piece of software. Like most software projects, the Subversion project makes use of an issue tracking tool to manage known outstanding issues with the software. But perhaps unlike most software projects, we try to keep our issue tracker relatively free of debris. It's not that we don't want to hear about Subversion's problems — after all, we can't fix what we don't know is broken. It's just that we've found a mismanaged issue tracker to be more of a hindrance than a help.
This mail pretty much says it all (except that nowadays you should post to the users@ list before posting to the dev@ list):
From: Karl Fogel <kfogel@collab.net>
Subject: Please ask on the list before filing a new issue.
To: dev@subversion.tigris.org
Date: Tue, 30 Jul 2002 10:51:24 (CDT)
Folks, we're getting tons of new issues, which is a Good Thing in
general, but some of them don't really belong in the issue tracker.
They're things that would be better solved by a quick conversation
here on the dev list. Compilation problems, behavior questions,
feature ideas that have been discussed before, that sort of thing.
*Please* be more conservative about filing issues. The issues
database is physically much more cumbersome than email. It wastes
people's time to have conversations in the issues database that should
be had in email. (This is not a libel against the issue tracker, it's
just a result of the fact that the issues database is for permanent
storage and flow annotation, not for real-time conversation.)
If you encounter a situation where Subversion is clearly behaving
wrongly, or behaving opposite to what the documentation says, then
it's okay to file the issue right away (after searching to make sure
it isn't already filed, of course!). But if you're
a) Requesting a new feature, or
b) Having build problems, or
c) Not sure what the behavior should be, or
d) Disagreeing with current intended behavior, or
e) Not TOTALLY sure that others would agree this is a bug, or
f) For any reason at all not sure this should be filed,
...then please post to the dev list first. You'll get a faster
response, and others won't be forced to use the issues database to
have the initial real-time conversations.
Nothing is lost this way. If we eventually conclude that it should be
in the issue tracker, then we can still file it later, after the
description and reproduction recipe have been honed on the dev list.
Thank you,
-Karl
The following are the policies that we ask folks to abide by when reporting problems or requested enhancements to Subversion.
First, make sure it's a bug. If Subversion does not behave the way you expect, look in the documentation and mailing list archives for evidence that it should behave the way you expect. Of course, if it's a common-sense thing, like Subversion just destroyed your data and caused smoke to pour out of your monitor, then you can trust your judgement. But if you're not sure, go ahead and ask on the users mailing list first, users@subversion.apache.org.
You should also search in the bug tracker to see if anyone has already reported this bug.
Once you've established that it's a bug, and that we don't know about it already, the most important thing you can do is come up with a simple description and reproduction recipe. For example, if the bug, as you initially found it, involves five files over ten commits, try to make it happen with just one file and one commit. The simpler the reproduction recipe, the more likely a developer is to successfully reproduce the bug and fix it.
When you write up the reproduction recipe, don't just write a prose description of what you did to make the bug happen. Instead, give a literal transcript of the exact series of commands you ran, and their output. Use cut-and-paste to do this. If there are files involved, be sure to include the names of the files, and even their content if you think it might be relevant. The very best thing is to package your reproduction recipe as a script; that helps us a lot. Here's an example of such a script: repro-template.sh for Unix-like systems and the Bourne shell, or repro-template.bat for Windows shell (contributed by Paolo Compieta); we'd welcome the contribution of a similar template script for other systems.
Quick sanity check: you *are* running the most recent version of Subversion, right? :-) Possibly the bug has already been fixed; you should test your reproduction recipe against the most recent Subversion development tree.
In addition to the reproduction recipe, we'll also need a complete description of the environment in which you reproduced the bug. That means:
Once you have all this, you're ready to write the report. Start out with a clear description of what the bug is. That is, say how you expected Subversion to behave, and contrast that with how it actually behaved. While the bug may seem obvious to you, it may not be so obvious to someone else, so it's best to avoid a guessing game. Follow that with the environment description, and the reproduction recipe. If you also want to include speculation as to the cause, and even a patch to fix the bug, that's great — see the patch submission guidelines.
Post all of this information to dev@subversion.apache.org, or if you have already been there and been asked to file an issue, then go to the issue tracker and follow the instructions there.
Thanks. We know it's a lot of work to file an effective bug report, but a good report can save hours of a developer's time, and make the bug much more likely to get fixed.
If the bug is in Subversion itself, send mail to users@subversion.apache.org. Once it's confirmed as a bug, someone, possibly you, can enter it into the issue tracker. (Or if you're pretty sure about the bug, go ahead and post directly to our development list, dev@subversion.apache.org. But if you're not sure, it's better to post to users@ first; someone there can tell you whether the behavior you encountered is expected or not.)
If the bug is in the APR library, please report it to both of these mailing lists: dev@apr.apache.org, dev@subversion.apache.org.
If the bug is in the Neon HTTP library, please report it to: neon@webdav.org, dev@subversion.apache.org.
If the bug is in the Apache Serf HTTP library, please report it to: dev@serf.apache.org, dev@subversion.apache.org.
If the bug is in Apache HTTPD 2.x, please report it to both of these mailing lists: dev@httpd.apache.org, dev@subversion.apache.org. The Apache httpd developer mailing list is high-traffic, so your bug report post has the possibility to be overlooked. You may also file a bug report at https://httpd.apache.org/bug_report.html.
If the bug is in your rug, please give it a hug and keep it snug.
Issue tracker milestones are an important aspect of how the Subversion developers organize their efforts and communicate with each other and with the Subversion user base. With the exception of some milestones used primarily when doing high-level issue triage, the project's issue tracker milestones tend to be named to reflect release version numbers and variations thereof. Milestones are used for slightly different purposes depending on the state of the issue, so it's important to understand those distinctions.
For open issues (those whose status is OPEN, IN PROGRESS, or REOPENED), the milestone indicates the Subversion release for which the developers are targeting the resolution of that issue. In the general case, we use milestones of the form MINORVERSION-consider to indicate that the resolution of an issue is being considered as something we'd like to release in MINORVERSION.0. For example, a feature we think we can and should add to Subversion 1.9.0 will get a 1.9-consider milestone. For obvious reasons, the accuracy of these release targets gets increasingly worse the farther into the future you look and, as such, users are encouraged to not treat them as binding promises from the developer community.
At any given time, there is work toward "the next big release" happening in the community. As that release begins to take shape, the developers will get a better feel for which issues are "must-haves" for the release (also known as "release blockers"), which ones are "nice-to-haves", and which ones should be deferred to a future release altogether. Issue milestones are the mechanism used to carry the results of those decisions. An issue that is deemed to be a release blocker will be moved from the MINORVERSION-consider milestone to the MINORVERSION.0 milestone; "nice-to-haves" will be left with the MINORVERSION-consider milestone; and issues deferred from the release will be re-milestoned either with ANOTHERMINORVERSION-consider or unscheduled, depending on whether we have a clear guess as to when the issue will be addressed.
Continuing the previous example, as development on Subversion 1.9.0-to-be progresses, developers will be evaluating that feature we planned for the release. If we believe that Subversion 1.9 should not be released without that feature, we'll change its milestone from 1.9-consider to 1.9.0; if we hope to release with that feature but don't want to commit to it, we'll leave the milestone as 1.9-consider; and if we know good and well we aren't going to get around to implementing the feature in the 1.9.x release series, we'll re-milestone the issue to something else (1.10-consider, perhaps).
The accuracy of the MINORVERSION.0 milestone is very important, as developers tend to use those issues to focus their efforts in the final days of a major release cycle.
For fixed issues (those whose status is RESOLVED and the resolution is FIXED), the issue milestone takes on a new utility: tracking the Subvesion release version which first carries the resolution of that issue. Regardless of the targeted release version for a given issue, once it is resolved its milestone should reflect the exact version number of the release which will first carry that resolution.
For other closed issues (those which aren't "open" and weren't really "fixed"), the issue milestone tends to mean pretty much nothing. There's little point in trying to maintain that tracker field when the issue itself is being effectively ignored because it's a duplicate, or because it's an invalid or inaccurate report.
Care must be taken when transitioning an issue between these states. An open issue that's been resolved needs to have its milestone adjusted to reflect the Subversion release which will first reflect that change. A resolved issue that gets backported to a previous release stream needs to have its milestone adjusted to point to that previous release's version number. Finally, a resolved issue that gets REOPENED needs to have its milestone reevaluated in terms of whether the issue is a release blocker (MINORVERSION.0) or not (MINORVERSION-consider). In such situations, it can be helpful to consult the issue's change history to see what milestone was used before the issue was resolved as fixed.
When an issue is filed, it goes into the special milestone "---", meaning unmilestoned. This is a holding area that issues live in until someone gets a chance to look at them and decide what to do.
The unmilestoned issues are listed first when you sort by milestone, and issue triage is the process of trawling through all the open issues (starting with the unmilestoned ones), determining which are important enough to be fixed now, which can wait until another release, which are duplicates of existing issues, which have been resolved already, etc. For each issue that will remain open, it also means making sure that the various fields are set appropriately: type, subcomponent, platform, OS, version, keywords (if any), and so on.
Here's an overview of the process (in this example, 1.5 is the next release, so urgent issues would go there):
for i in issues_marked_as("---"):
if issue_is_a_dup_of_some_other_issue(i):
close_as_dup(i)
elif issue_is_invalid(i):
# A frequent reason for invalidity is that the reporter
# did not follow the "buddy system" for filing.
close_as_invalid(i)
elif issue_already_fixed(i):
version = fixed_in_release(i)
move_to_milestone(i, version)
close_as_fixed(i)
elif issue_unreproducible(i):
close_as_worksforme(i)
elif issue_is_real_but_we_won't_fix_it(i):
close_as_wontfix(i)
elif issue_is_closeable_for_some_other_reason(i):
close_it_for_that_reason(i)
# Else issue should remain open, so DTRT with it...
# Set priority, environment, component, etc, as needed.
adjust_all_fields_that_need_adjustment(i)
# Figure out where to put it.
if issue_is_a_lovely_fantasy(i):
move_to_milestone(i, "blue-sky")
if issue_is_not_important_enough_to_block_any_particular_release(i):
move_to_milestone(i, "nonblocking")
elif issue_resolution_would_require_incompatible_changes(i):
move_to_milestone(i, "2.0-consider")
elif issue_hurts_people_somewhat(i):
move_to_milestone(i, "1.6-consider") # or whatever
elif issue_hurts_people_a_lot(i):
move_to_milestone(i, "1.5-consider")
elif issue_hurts_and_hurts_and_should_block_the_release(i):
move_to_milestone(i, "1.5")
This document is for information about how Subversion developers respond to security issues. To report an issue, please see the Security reporting instructions.
Subversion's first job is keeping your data safe. To do that, the Subversion development community takes security very seriously. One way we demonstrate this is by not pretending to be cryptography or security experts. Rather than writing a bunch of proprietary security mechanisms for Subversion, we prefer instead to teach Subversion to interoperate with security libraries and protocols provided by those with knowledge of that space. For example, Subversion defers wire encryption to the likes of OpenSSL. It defers authentication and basic authorization to those mechanisms provided by Cyrus SASL or by the Apache HTTP Server and its rich collection of modules. To the degree that we can leverage the knowledge of security experts by using the third-party libraries and APIs they provide, we will continue to do so.
This document describes the steps we take when receiving or finding an issue which may be classified as having security implications, and is meant to suppliment the Apache guidelines to committers for the same.
Security problems should be discussed on private@subversion.apache.org + security@apache.org. security@subversion.apache.org is a convenience alias that targets these two lists. (Note that unlike, say, security@httpd.a.o, it is not a mailing list, so you can't subscribe/unsubscribe to it separately.)
We publish the list of previous security advisories at: https://subversion.apache.org/security/
We track in-progress issues in the PMC's private repository: https://svn.apache.org/repos/private/pmc/subversion/security
We aim to follow a published procedure.
We usually follow the ASF's recommended procedure. We usually also do pre-notification to pre-selected parties; details of this are managed in the PMC's private repository.
We also have a different procedure which we may use, documented in How to Roll Releases in Private. At present we do not usually use this procedure.
This document can generally be broken into three parts, in increasing order of specificity:
Subversion release managers use a set of steps codified in a Python script named release.py. This script can be used to perform most of the automated steps in the release process. Run it with the -h option to get more information.
In addition to the following project-specific guidelines, aspiring release managers may also want to read up on the general Apache release policies. They can seem a bit patchwork at times, but give a good idea of general best practice and how Subversion fits in the larger ASF ecosystem.
Subversion uses "MAJOR.MINOR.PATCH" release numbers. We do not use the "even==stable, odd==unstable" convention; any unqualified triplet indicates a stable release:
1.0.1 --> first stable patch release of 1.0 1.1.0 --> next stable minor release of 1.x after 1.0.x 1.1.1 --> first stable patch release of 1.1.x 1.1.2 --> second stable patch release of 1.1.x 1.2.0 --> next stable minor release after that
The order of releases is semi-nonlinear — a 1.0.3 might come out after a 1.1.0. But it's only "semi"-nonlinear because eventually we declare a patch line defunct and tell people to upgrade to the next minor release, so over the long run the numbering is basically linear.
The numbers may have multiple digits. For example, 1.7.19 is the nineteenth patch release in the 1.7.x line; it was released three years after 1.7.2, and three months before 1.7.20.
Subversion releases may be qualified by text following the version number, which all represent various steps in the pre-release process. In order from least- to most-stable:
| Qualifier | Meaning | Example | Output of svn --version |
|---|---|---|---|
| Alpha | We know or expect there to be problems, but solicit testing from interested individuals. | subversion-1.7.0-alpha2 | version 1.7.0 (Alpha 2) |
| Beta | We don't expect there to be problems, but be wary just in case. | subversion-1.7.0-beta1 | version 1.7.0 (Beta 1) |
| RC (Release Candidate) | This release is a candidate to become the final proposed version. If no serious bugs are found, the -rc tag will be dropped, and the contents of this release will be declared stable. | subversion-1.7.0-rc4 | version 1.7.0 (Release Candidate 4) |
When you 'make install' subversion-1.7.0-rc1, it still installs as though it were "1.7.0", of course. The qualifiers are metadata on the release; we want each subsequent prerelease release to overwrite the previous one, and the final release to overwrite the last prerelease.
For working copy builds, there is no tarball name to worry about, but 'svn --version' still produces special output:
version 1.7.1-dev (under development)
The version number is the next version that project is working towards. The important thing is to say "under development". This indicates that the build came from a working copy, which is useful in bug reports.
When we want new features to get wide testing before we enter the formal stabilization period, we'll sometimes release alpha and beta tarballs. There is no requirement to do any beta releases even if there were "alpha1", "alpha2", etc releases; we could just jump straight to "rc1". However, there are circumstances where a beta can be useful: for example, if we're unsure of a UI decision and want to get wider user feedback before solidifying it into a formal release candidate.
Alphas and betas are only for people who want to help test, and who understand that there may be incompatible changes before the final release. The signature requirements are at the release manager's discretion. Typically, the RM will require only 1 or 2 signatures for each platform, and to tell signers that they can still sign even if their testing reveals minor failures, as long as they think the code is solid enough to make testing by others worthwhile. The RM should request that signers include a description of any errors along with their signatures, so the problems can be published when the alpha or beta release is announced.
When the alpha or beta is publicly announced, distribution packagers should be firmly warned off packaging it. See this mail from Hyrum K. Wright for a good model.
Our compatibility rules (as detailed below) only start to apply once a final x.y.0 version has been blessed and released. Any API's, wire protocols, and on-disk formats that appeared on trunk or in an alpha/beta/rc pre-release are not subject to any compatibility promises; we may change them arbitrarily until the final release, if we find a good reason to do so. We might even remove entirely an interface or serialization format that we are not comfortable with.
This is particularly a problem for persistent data (working copies and repositories), since we might not provide an upgrade path—code paths or designated scripts for the legacy format—with the final release. (Of course, we might provide such scripts for the benefit of developers and users who test our pre-releases; but we do not obligate ourselves to do so.) Consequently, pre-releases should never be trusted with any data meant for long-term safe-keeping.
At the same time, we wish to remind the reader that the best time to point out API design bugs is before they are released and set in stone—in other words, during the initial design and pre-release stages.
If a release or candidate release needs to be quickly re-issued due to some non-code problem (say, a packaging glitch), it's okay to reuse the same name, as long as the tarball hasn't been blessed by signing yet. However, if it has been uploaded to the standard distribution area with signatures, or if the re-issue was due to a change in code a user might run, then the old name must be tossed and the next name used.
If the old name is tossed before the would-be release tarball was published and announced to users, the tossed name is considered a non-public release, and documentation (such as CHANGES and the tag's log message) should be updated to reflect that. (See 1.8.7 for an example.) Tags and tarballs of tossed releases remain in the repository history, but they are not supported for general use (on the contrary, they are known to have release-blocker bugs).
Subversion follows strict compatibility, with the same guidelines as APR (see https://apr.apache.org/versioning.html), plus a few extensions, described later. These guidelines are in place to ensure various forms of client/server interoperability, and make sure users have a clear upgrade path between MAJOR.MINOR Subversion releases.
Compatibility can span a number of axes: everything from APIs and ABIs to command line output formats. We try to balance the need to modify the existing architecture to support new features, while still supporting current users to the greatest extent possible. The general idea is:
Upgrading/downgrading between different patch releases in the same MAJOR.MINOR line never breaks code. It may cause bugfixes to disappear/reappear, but API signatures and semantics remain the same. (Of course, the semantics may change in the trivial ways appropriate for bugfixes, just not in ways that would force adjustments in calling code.)
Upgrading to a new minor release in the same major line may cause new APIs to appear, but not remove any APIs. Any code written to the old minor number will work with any later minor number in that line. However, downgrading afterwards may not work, if new code has been written that takes advantage of the new APIs.
(Occasionally, bugs are found which require the behavior of old APIs to be modified slightly. This typically only manifests itself in various corner cases and other uncommon areas. These changes are documented as API errata for each MAJOR.MINOR release.)
When the major number changes, all bets are off. This is the only opportunity for a full reset of the APIs, and while we try not to gratuitously remove interfaces, we will use it to clean house a bit.
Subversion extends the APR guidelines to cover client/server compatibility questions:
A patch or minor number release of a server (or client) never breaks compatibility with a client (or server) in the same major line. However, new features offered by the release might be unsupported without a corresponding upgrade to the other side of the connection. For updating ra_svn code specifically, please observe these principles:
Fields can be added to any tuple; old clients will simply ignore them. (Right now, the marshalling implementation does not let you put number or boolean values in the optional part of a tuple, but changing that will not affect the protocol.)
We can use this mechanism when information is added to an API call.
At connection establishment time, clients and servers exchange a list of capability keywords.
We can use this mechanism for more complicated changes, like introducing pipelining or removing information from API calls.
New commands can be added; trying to use an unsupported command will result in an error which can be checked and dealt with.
The protocol version number can be bumped to allow graceful refusal of old clients or servers, or to allow a client or server to detect when it has to do things the old way.
This mechanism is a last resort, to be used when capability keywords would be too hard to manage.
Working copy and repository formats are backward- and forward-compatible for all patch releases in the same minor series. They are forward-compatible for all minor releases in the same major series; however, a minor release is allowed to make a working copy or repository that doesn't work with previous minor releases, where "make" could mean "upgrade" as well as "create".
Occasionally, security issues are reported or discovered in the Subversion which warrant special treatment when releasing. The general release process is the same, and details of how the developers treat these issues is covered elsewhere.
Subversion does not distribute binary packages, but instead relies upon third-party packagers to do so. Luckily, many individuals and companies have stepped in to volunteer their efforts in this regard, and we are grateful for their efforts.
If you are a third-party packager, you may encounter instances when a bug fix or other change is important for your users, and you want to get it to them more quickly than the standard Subversion release cycle. Or you may maintain a set of patches locally which benefit your target audience. If possible, it is preferred to use the patch process and have your changes accepted and applied to trunk to be released on the normal Subversion release schedule.
However, if you feel that you need to make changes that would not be widely accepted by the Subversion developer community, or need to provide early access to unreleased features, you should follow the guidelines below. They are intended to help prevent confusion in the user community, and make both your distribution and the official Subversion releases as successful as possible.
First, make sure you follow the ASF trademark policy. You will need to differentiate your release from the standard Subversion releases to reduce any potential confusion caused by your custom release.
Second, consider creating a branch in the public Subversion repository to track your changes and to potentially allow your custom changes to be merged into mainline Subversion. (If you do not have it already, ask for commit access.)
Third, if your custom release is likely to generate bug reports that would not be relevant to mainline Subversion, please stay in touch with the users of the custom release so you can intercept and filter those reports. But of course, the best option would be not to be in that situation in the first place — the more your custom release diverges from mainline Subversion, the more confusion it invites. If you must make custom releases, please try to keep them as temporary and as non-divergent as possible.
When a new, improved version of an API is introduced, the old one remains for compatibility, at least until the next major release (2.0.0). However, we mark the old one as deprecated and point to the new one, so people know to write to the new API if at all possible. When deprecating, mention the release after which the deprecation was introduced, and point to the new API. If possible, replace the old API documentation with a diff to the new one. For example:
/**
* Similar to svn_repos_dump_fs3(), but with a @a feedback_stream instead of
* handling feedback via the @a notify_func handler
*
* @since New in 1.1.
* @deprecated Provided for backward compatibility with the 1.6 API.
*/
SVN_DEPRECATED
svn_error_t *
svn_repos_dump_fs2(svn_repos_t *repos,
svn_stream_t *dumpstream,
svn_stream_t *feedback_stream,
svn_revnum_t start_rev,
svn_revnum_t end_rev,
svn_boolean_t incremental,
svn_boolean_t use_deltas,
svn_cancel_func_t cancel_func,
void *cancel_baton,
apr_pool_t *pool);
When the major release number changes, the "best" new API in a
series generally replaces all the previous ones (assuming it subsumes
their functionality), and it will take the name of the original API.
Thus, marking 'svn_repos_dump_fs' as deprecated in
1.1.x doesn't mean
that 2.0.0 doesn't have 'svn_repos_dump_fs', it just means the
function's signature will be different: it will have the signature
held by svn_repos_dump_fs2
(or svn_repos_dump_fs3, or whatever) in
1.1.x. The numbered-suffix names disappear, and there is a single
(shiny, new) svn_repos_dump_fs again.
One exception to this replacement strategy is when the old function has a totally unsatisfying name anyway. Deprecation is a chance to fix that: we give the new API a totally new name, mark the old API as deprecated, point to the new API; then at the major version change, we remove the old API, but don't rename the new one to the old name, because its new name is fine.
Minor and major number releases go through a stabilization period before release, and remain in maintenance (bugfix) mode after release. To start the release process, we create an "A.B.x" branch based on the latest trunk.
The stabilization period for a new A.B.0 release normally lasts four weeks, and allows us to make conservative bugfixes and discover showstopper issues. The stabilization period begins with a release candidate tarball with the version A.B.0-rc1. Further release candidate tarballs may be made as blocking bugs are fixed; for example, if a set of language bindings is found to be broken, it is prudent to make a new release candidate when they are fixed so that those language bindings may be tested.
Once the A.B.x branch has been created, no source code changes are ever committed to it directly; changes are backported from trunk to the A.B.x branch after being voted on, by the process described in the next sections.
At the beginning of the final week of the stabilization period, a new release candidate tarball should be made if there are any showstopper changes pending since the last one. The final week of the stabilization period is reserved for critical bugfixes; fixes for minor bugs should be deferred to the A.B.1 release. A critical bug is a non-edge-case crash, a data corruption problem, a major security hole, or something equally serious.
Under some circumstances, the stabilization period will be extended:
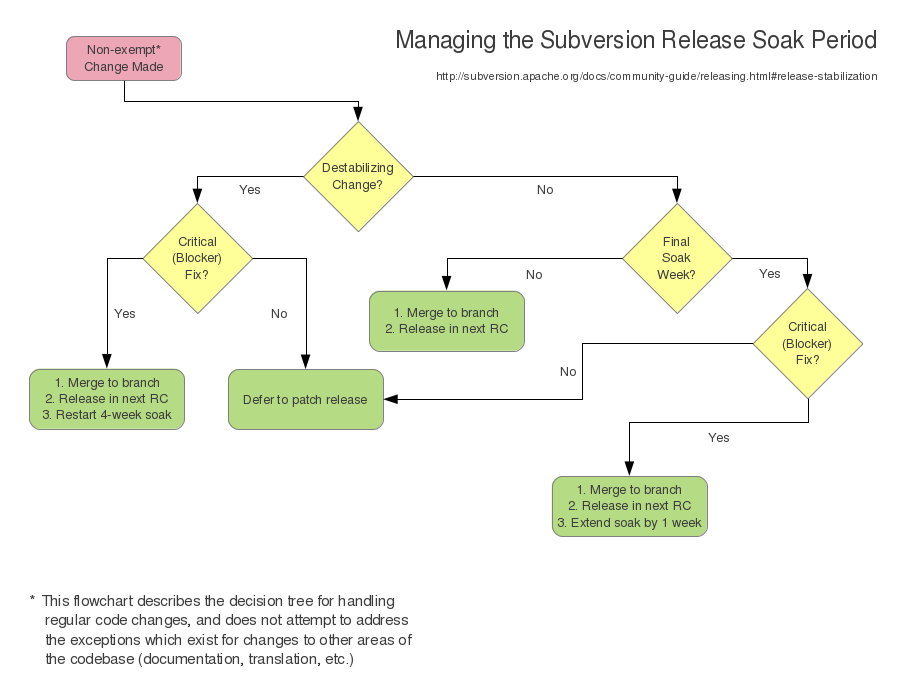
svn-soak-management.png
If a potentially destabilizing change must be made in order to fix a bug, the entire four-week stabilization period is restarted. A potentially destabilizing change is one which could affect many parts of Subversion in unpredictable ways, or which involves adding a substantial amount of new code. Any incompatible API change (only allowable in the first place if the new release is an A.0.0 release) should be considered a potentially destabilizing change.
If a critical bugfix is made during the final week of the stabilization period, the final week is restarted. The final A.B.0 release is always identical to the release candidate made one week before (with the exceptions discussed below).
After the A.B.0 release is out, patch releases (A.B.1, A.B.2, etc.) follow when bugfixes warrant them. Patch releases do not require a four week soak, because only conservative changes go into the line.
Certain kinds of commits can go into A.B.0 without restarting the soak period, or into a later release without affecting the testing schedule or release date:
Without voting:
Changes to the STATUS file.
Documentation fixes.
Changes that are a normal part of release bookkeeping, for example, the steps listed in Rolling a release and Creating and maintaining release branches.
Changes to dist.sh by, or approved by, the release manager.
Changes to message translations in .po files or additions of new .po files.
With voting:
Anything affecting only tools/, packages/, or bindings/.
Changes to printed output, such as error and usage messages, as
long as format string "%" codes and their args are not
touched.
NOTE: The requirements on message translation changes are looser than for text messages in C code. Changing format specifiers in .po files is allowed because their validity can be checked mechanically (with the -c flag on msgfmt of GNU gettext). This is done at build time if GNU gettext is in use.
Core code changes, of course, require voting, and restart the soak or test period, since otherwise the change could be undertested.
A change to the A.B.x line must be first proposed in the A.B.x/STATUS file. Each proposal consists of a short identifying block (e.g., the revision number of a trunk or related-line commit, or perhaps an issue number), a brief description of the change, an at-most-one-line justification of why it should be in A.B.x, perhaps some notes/concerns, and finally the votes. The notes and concerns are meant to be brief summaries to help a reader get oriented. Don't use the STATUS file for actual discussion; use dev@ instead.
Here's an example, probably as complex as an entry would ever get:
* r98765 (issue #56789)
Make commit editor take a closure object for future mindreading.
Justification:
API stability, as prep for future enhancement.
Branch: 1.8.x-r98765
Notes:
There was consensus on the desirability of this feature in
the near future; see thread at http://... (Message-Id: blahblah).
Merge with --accept=mc.
Concerns:
Vetoed by jerenkrantz due to privacy concerns with the
implementation; see thread at http://... (Message-Id: blahblah)
Votes:
+1: ghudson, bliss
+0: cmpilato
-0: gstein
-1: jerenkrantz
Anyone may vote, but only full committers and partial committers for the involved areas have binding votes. When committers cast a non-binding vote (such as a partial committer voting for a change outside his nominated area), they should annotate their vote as non-binding, like this:
* r31833
svndumpfilter: Don't match prefixes to partial path components.
Fixes #desc4 of issue #1853.
Votes:
+1: danielsh, hwright
+1 (non-binding): stylesen
This distinction is made in all kinds of voting—backport voting, release voting, and the mythical votes caused by failure to reach consensus—but for different reasons. In release votes, this distinction is legally required for the release to enter ASF's legal shield, whereas in backport votes, it's closer to being an advisory distinction. After all, if someone votes -1 on a change for a sound reason, their accreditations don't matter; if their analysis is correct, the change won't be backported. Likewise, if a change fails to receive the required number of binding +1 votes but has some non-binding +1 votes, that may help it be approved.
In other words, the purpose of the backport process is to ensure destabilizing changes won't enter patch releases. Voting serves that purpose by forcing each change to undergo a certain amount of review. Since karma is not transferable, we measure "amount of review" in terms of binding votes—but as ever, anyone can give input to the process and be listened to.
The voter's opinion of a change is encoded as +1, -1, +0, or -0.
Define "veto" or refer to a definition
If you cast a veto (i.e. -1), please state the reason in the concerns field, and include a url / message-id for the list discussion if any. You can go back and add the link later if the thread isn't available at the time you commit the veto.
A -0 vote means you somewhat object to a change—state your reasons in on dev@, or summarize them in a parenthetical—but won't stand in the way of consensus.
Voting +1 on a change doesn't just mean you approve of it in principle. It means you have thoroughly reviewed the change, and find it correct and as nondisruptive as possible. When it is committed to the release branch, the log message will include the names of all who voted for it, as well as the original author and the person making the commit. All of these people are considered equally answerable for bugs. Committers are trusted to know what they don't know and not cast +1 votes lightly.
If you've reviewed a patch, and like it but have some reservations, you can write "+1 (concept)" and then ask questions on the list about your concerns. You can write "+0" if you like the general idea but haven't reviewed the patch carefully. Neither of these votes counts toward the total, but they can be useful for tracking down people who are following the change and might be willing to spend more time on it.
For a non-LTS ("regular") release line, a change is approved if it receives two +1s and no vetoes. (Only binding votes count; see above.)
For an LTS release line, a change is approved if it receives three +1s and no vetoes. (Only binding votes count; see above.)
Notwithstanding the above, for any release line, a change that affects only areas that are not core code (for example, tools/, packages/, bindings/, test scripts, etc.), and that does not affect the build system, can go in with one +1 from a full committer or a partial committer for that area, at least one +0 or "concept +1" from any other committer, and no vetoes.
The goal is to get at least two pairs of eyes on the change, without demanding that every reviewer have the same amount of expertise as the area maintainer. This way one can review for general sanity, accurate comments, obvious mistakes, etc, without being forced to assert "Yes, I understand these changes in every detail and have tested them."
Before proposing a change in STATUS, you should try merging it onto the branch to ensure that it doesn't produce merge conflicts. If conflicts occur, please create a new temporary branch from the release branch with your changes merged and the conflicts resolved. The branch should be named A.B.x-rYYYY, where YYYY is the first revision of your change in the STATUS file. Add a note in the STATUS file about the existence of the temporary branch in the form of a Branch: A.B.x-rYYYY or Branch: ^/subversion/branches/A.B.x-rYYYY header (use this exact form; scripts parse it). If the change involves further work, you can merge those revisions to the branch. When the entry for this change is removed from STATUS, this temporary branch should also be removed to avoid cluttering the /branches directory.
A temporary branch is also used in the rare case that a change should be made to the A.B.x branch that isn't a backport of a change from trunk.
If you nominate an entry that causes merge conflicts until another nomination is merged, note that in the nomination. Put a "Depends:" header in the entry; that will keep the hourly "detect nominations with merge conflict" buildbot job green. (The value of the "Depends:" header is not parsed.)
The tools/dist/nominate.pl script (in trunk) automates the process of adding a new nomination. The same script also has a REPL loop that helps with the process of reviewing nominations and casting votes; see tools/dist/README.backport (in trunk).
NOTE: Changes to STATUS regarding the temporary branch, including voting, are always kept on the main release branch.
When adding revisions to a nomination that others have already voted on, annotate their entries with "(rX only)" to clarify what parts they have and haven't voted on, like this:
* r30643, r30653, r30785
Update bash completion script.
Votes:
+1: arfrever (r30785 only), stylesen
Obvious fixes do not require '(rX only)' to be mentioned.
If you commit someone else's vote that was communicated via other means, note that in your log message.
Before the actual release, send an e-mail to the translators to request updates of the .po files. Take their e-mail addresses from the COMMITTERS file in trunk, using a command such as:
sed -e '/^ *Translat.*:$/,/:$/!d' -e 's/^ *[^ ]* *\([^>]*>\).*/\1/;t;d' COMMITTERS
Include a translation status report produced by:
./tools/po/l10n-report.py
This should be done after all localised strings have stabilised in their final form for the release, but sufficiently in advance of the actual release to allow the translators to do their work. As a rule of thumb, send the notification at the least one week, preferably more, prior to the intended release. If many strings have changed, as would be the case for the first release from a new branch, then let more time pass.
So, a release branch has stabilized, and you are gearing up to roll the release. The details of the rolling process are automated by the release.py helper script. To run this script, you'll need a Subversion trunk working copy. Run release.py -h to get a list of available subcommands.
Before you can actually roll the archives, you need to set up a white-room rolling environment. This environment must contain pristine versions of some build tools.
It is important that you do not use distribution shipped versions of this software as they are often patched in ways that are not portable (e.g., Debian's libtool patch: #291641, #320698.) The version numbers given in tools/dist/release-lines.yaml should normally be reconsidered and increased to the latest stable upstream release in the time leading up to an A.B.0 release. Changing the version within an A.B.x series should only be done with careful consideration.
Autoconf, Libtool and SWIG: Pick a directory to contain your special build tools for Subversion RM duties - for example /opt/svnrm. Configure, build and install the three pieces of software with the release.py build-env command.
mkdir -p /opt/svnrm && cd /opt/svnrm && $SVN_SRC_DIR/tools/dist/release.py build-env X.Y.Z
The rolling scripts also require the following commands to be available: pax, xgettext, m4, and python -c 'import yaml'.
Install these from your OS packages. (On Debian systems, that'd be apt install pax gettext m4 python-yaml subversion.)
Before rolling:
Create the tarballs: Run:
./release.py roll X.Y.Z 1234When release.py is done you'll have tarballs within the /opt/svnrm/deploy directory.
Test one or both of the tarballs:
a) tar zxvf subversion-X.Y.Z.tar.gz; cd subversion-X.Y.Z
b) ./configure
See INSTALL, section III.B for detailed instructions on
configuring/building Subversion.
If you installed Apache in some place other than the default, as
mentioned above, you will need to use the same
--prefix=/usr/local/apache2 option as used to configure Apache.
You may also want to use --enable-mod-activation, which will
automatically enable the required Subversion modules in the
Apache config file.
c) make
d) make check
e) make install (this activates mod_dav)
f) make davcheck
For this, start up Apache after having configured according to
the directions in subversion/tests/cmdline/README.
Make sure, that if you maintain a development installation of
apache, that you check the config file and update it for the
new release area where you're testing the tar-ball.
(Unless you rename the tree which gets extracted from the
tarball to match what's in httpd.conf, you will need to edit
httpd.conf)
g) make svncheck
First, start up svnserve with these args:
$ subversion/svnserve/svnserve -d -r \
`pwd`/subversion/tests/cmdline
-d tells svnserve to run as a daemon
-r tells svnserve to use the following directory as the
logical file system root directory.
After svnserve is running as a daemon 'make svncheck' should run
h) Then test that you can check out the Subversion repository
with this environment:
subversion/svn/svn co https://svn.apache.org/repos/asf/subversion/trunk
i) Verify that the perl, python, and ruby swig bindings at least compile.
If you can't do this, then have another developer verify.
(see bindings/swig/INSTALL for details)
Ensure that ./configure detected a suitable version of swig,
perl, python, and ruby. Then:
make swig-py
make check-swig-py
sudo make install-swig-py
make swig-pl
make check-swig-pl
sudo make install-swig-pl
make swig-rb
make check-swig-rb
sudo make install-swig-rb
j) Verify that the javahl bindings at least compile.
If you can't do this, then have another developer verify.
(see subversion/bindings/javahl/README for details)
Ensure that ./configure detected a suitable jdk, and then
possibly re-run with '--enable-javahl', '--with-jdk=' and
'--with-junit=':
make javahl
sudo make install-javahl
make check-javahl
k) Verify that the ctypes python bindings at least compile.
If you can't do this then have another developer verify.
(see subversion/bindings/ctypes-python/README for details)
Ensure that ./configure detected a suitable ctypesgen, and
then possibly re-run with '--with-ctypesgen':
make ctypes-python
sudo make install-ctypes-python
make check-ctypes-python
l) Verify that get-deps.sh works and does not emit any errors.
./get-deps.sh
Use GnuPG to sign release:
Use release.py to sign the release:
release.py sign-candidates X.Y.Z
This will run the equivalent of the following commands for you:
gpg -ba subversion-X.Y.Z.tar.bz2
gpg -ba subversion-X.Y.Z.tar.gz
gpg -ba subversion-X.Y.Z.zip
and append gpg signatures to the corresponding .asc files.
Subversion Operations
Create the tag with the svn_version.h that reflects the final release. You do this using:
release.py create-tag X.Y.Z 1234
Note: Please always make a tag, even for release candidates.
create-tag will bump the version number in the STATUS and svn_version.h files for the original branch. If you just did 1.0.2 then both files should have the proper value for 1.0.3 and so on.
Commit the tarballs, signatures and checksums to https://dist.apache.org/repos/dist/dev/subversion There is a release.py subcommand that automates this step:
release.py post-candidates 1.7.0
Announce that the candidates are available for testing and signing:
send an email to the dev@ list, something like this:
Subject: Subversion X.Y.Z up for testing/signing The X.Y.Z release artifacts are now available for testing/signing. Please get the tarballs from https://dist.apache.org/repos/dist/dev/subversion and add your signatures there. Thanks!
adjust the topic on #svn-dev to mention "X.Y.Z is up for testing/signing"
Update the issue tracker to have appropriate versions/milestones. If releasing a new minor release a version for 1.MINOR.x should be added. All releases should add a version for the next release (i.e. 1.MINOR.x+1). If you do not have permissions to do so please send an email to the dev@ list.
Subversion releases are distributed through a global Content Distribution Network (CDN). (This replaced the former ASF mirror network as of late 2021. Nevertheless, there may exist other organizations that choose to continue mirroring ASF releases.)
It is important that end-users be able to verify the authenticity of the source code packages they download. Checksums are sufficient to detect corruption in the download process, but to prevent a malicious individual or mirror operator from distributing replacement packages, each source code package must be cryptographically signed by members of the Subversion PMC. These signatures are done using each committer's private PGP key, and are then published with the release so that end users can verify the integrity of the downloaded packages.
Before a Subversion release is officially made public, it requires:
When creating the initial set of tarballs, the release manager will also create the first set of signatures. While the tarballs themselves may be built on people.apache.org, it is important that the signatures are not generated there. Signing tarballs requires a private key, and storing private keys on ASF hardware is strongly discouraged. After signing the tarballs (using the process below) the release manager should upload the signatures to the preliminary distribution location, and place them in the same directory as the tarballs.
Members of the PMC, as well as enthusiastic community members are encouraged to download the tarballs from the preliminary distribution location, run the tests, and then provide their signatures. The public keys for these signatures should be included in the ASF LDAP instance through id.apache.org. (A list of the current public keys of Subversion committers and PMC members is autogenerated from LDAP each day.) The release manager is encouraged to wait at least 5 days for the signatures before announcing the release to allow anybody testing the version to complete signing the release before its announcement.
Signing a tarball means that you assert certain things about it. When announcing your signature, indicate in the mail what steps you've taken to verify that the tarball is correct, such as verifying the contents against the proper tag in the repository. Running make check over all RA layers and FS backends is also a good idea, as well as building and testing the bindings.
To obtain the release candidate, check out a working copy of https://dist.apache.org/repos/dist/dev/subversion. Verify the release manager's PGP signatures on the tarballs. release.py automates this step:
release.py get-keys
release.py --target /path/to/dist/dev/subversion/wc check-sigs 1.7.0-rc4
After having verified, extracted, and tested the tarball, you should sign by creating an armored detached signature using gpg. To append your signature to a .asc file, use a command like:
gpg -ba -o - subversion-1.7.0-rc4.tar.bz2 >> subversion-1.7.0-rc4.tar.bz2.asc
The release.py script can automate this step:
release.py --target /path/to/dist/dev/subversion/wc sign-candidates 1.7.0-rc4
After adding your signatures, commit the locally modified .asc files to the dist.apache.org repository.
If you've downloaded and tested a .tar.bz2 file, it is possible to sign a .tar.gz file with the same contents without having to download and test it separately. The trick is to extract the .bz2 file, and pack it using gzip like this:
bzip2 -cd subversion-1.7.0-rc4.tar.bz2 \
| gzip -9n > subversion-1.7.0-rc4.tar.gz
The resulting file should be identical to the file generated by the release manager, and thus can be signed as described above. To verify that the files are identical, you may use either the checksums or the release manager's signature, both of which should be provided with the tarballs.
But, if the checksum is not identical it doesn't have to be the case that the file signature is wrong, or the file has been tampered with. It could very well be the case that you don't have an identical gzip version as the release manager.
After the tarballs are created, and all the signatures are created and validated, the release is ready for publication. This section outlines the steps needed to publish a Subversion release.
Subversion artifacts are distributed through a global Content Distribution Network (CDN). The source code download page automatically assists users in selecting a suitable download link. We usually host only the latest stable release for the supported release lines on the project's distribution directory, while all previous Subversion releases are available in the archives.
To upload a release to the CDN:
release.py move-to-dist 1.7.0This moves the tarballs, signatures and checksums from ^/dev/subversion to ^/release/subversion. It takes the content delivery network (CDN) approximately 15 minutes to pick up the new release. The archive will also automatically pick up the release. Although running move-to-dist will move the signature files, committers are still able to commit new signatures to ^/release/subversion; however it will take up to 15 minutes for those signatures to appear on the CDN. Any such signatures cannot be included in the release announcement unless 15 minutes have passed since they were committed.
At this point, the release may be publicly available, but its still a good idea to hold off on announcing it until after the CDN has picked it up. After the 15 minute period has passed, giving the CDN enough time to sync, the release manager will send the announcement and publish the changes to the Subversion website, as described below.
It's also a good time to clean out any old releases from ^/release/subversion; only the most recent release for each supported release line should be in that directory. Releases that have been available at ^/release/subversion for at least 24 hours will continue to remain available in the archives. You can clean old releases using:
release.py clean-dist
Submit the version number of the new release on reporter.apache.org. The following command
curl -u USERNAME "https://reporter.apache.org/addrelease.py?date=`date +%s`&committee=subversion&version=VERSION&xdate=`date +%F`"will add the release, it should probably be added to release.py.
Even though the steps below indicate to update the published website directly, you may prepare the changes on ^/subversion/site/staging. In that case:
Do a catch-up merge from ^/subversion/site/publish.
Commit any changes to ^/subversion/site/staging and check the results on https://subversion-staging.apache.org.
When ready to publish, merge the changes back to ^/subversion/site/publish (review the merge in case there are other changes on staging not ready to be merged).
For any release, including pre-releases (alpha/beta/rc):
Edit ^/subversion/site/publish/download.html to note the latest release. Use release.py write-downloads to generate the table. If this is a stable release, update the [version] or [supported] ezt macro definition (e.g. [define version]1.7.0[end]); If this is a pre-release, uncomment the <div id="pre-releases">; if this is a 1.x.0 release that obsoletes the pre-release, comment it back out.
Add new News item to ^/subversion/site/publish/news.html announcing the release. Add the same item to the News list on ^/subversion/site/publish/index.html, also removing the oldest News item from that page. Use release.py write-news to generate a template news item, which should then be customized. In the news item there is a section that should contain a link to the announcement mail. For now it is commented out, the link is added later. Check that the date is correct if you generated the template in advance of the release date.
In addition, if this is a stable release X.Y.Z (not alpha/beta/rc):
List the new release on ^/subversion/site/publish/doap.rdf
There should be a <release> section for each supported minor release with the <created> and <revision> being updated to the current release date and patch release number. Do not change anything else in the file (in particular the <created> under <Project> is the date when the Subversion project was created).
List the new release on ^/subversion/site/publish/docs/release-notes/release-history.html
In addition, if this is a new minor release X.Y.0:
Update the community release support levels on the "Supported Versions" section of ^/subversion/site/publish/docs/release-notes/index.html
Update supported_release_lines in release.py, removing old lines as necessary.
Remove the "draft" warning from ^/subversion/site/publish/docs/release-notes/X.Y.html
Create or update the versioned documentation snapshots in ^/site/publish/docs/api/X.Y and ^/site/publish/docs/javahl/X.Y, and ensure that the "latest" symlinks which are siblings of those directories always point to the directories of the latest release series.
Example:
VER=1.12 DOCS_WC=~/src/svn/site/staging/docs TAG_BUILD_DIR=~/src/svn/tags/$VER.x/obj-dir cd $TAG_BUILD_DIR make doc cp -a doc/doxygen/html $DOCS_WC/api/$VER cp -a doc/javadoc $DOCS_WC/javahl/$VER for D in $DOCS_WC/api $DOCS_WC/javahl; do svn add $D/$VER rm $D/latest && ln -s $VER $D/latest done svn ci -m "In 'staging': Add $VER API docs." $DOCS_WC/api $DOCS_WC/javahl
Update the links to the API docs on the index page docs/index.html#api.
Commit the modifications to "publish" (or merge them from "staging" to "publish") on the release date.
New minor releases (numbered 1.x.0) may be accompanied by press releases. All details of the prospective press release are handled on the private@ list, in coordination with press@a.o.
As a rule of thumb, start a thread on private@ / press@ at the start of the soak; it is better to give press@ too long an advance warning than too short one.
Write a release announcement, referring to previous ones for guidance. Remember to include the URL and checksums in the announcement! The release.py write-announcement subcommand creates a template announcement which can be customized for specific circumstances. If the release fixes security issues, pass the --security flag, in order to generate the correct Subject, Cc, and description in the output.
If the community support levels are changing with this release, be sure to update the recommended_release variable in release.py before using it to generate the announcement.
Send the announcement from your @apache.org email address. (Mail to announce@ will bounce if sent from any other address. For best results, follow the instructions on the committer email page and send your message through the official mail relay.) Ensure that your mailer doesn't wrap the URLs over multiple lines.
NOTE: We update the website before announcing the release to make sure any links in the release announcement are valid. After announcing the release, links to the release announcement e-mail are added to the website.
There are two announce@ mailing lists where the release announcement gets posted: The Subversion project's announce@subversion.apache.org list, and the ASF-wide announce@apache.org list. It is possible that your message to the ASF-wide announce@ list will be rejected. This generates a moderation notification with a Subject line such as: Returned post for announce@apache.org. The moderator who ordered the mailing list software to reject the message may neglect to sign their name to the rejection message, making the rejection anonymous, and the grounds for the rejection may be invalid. Be that as it may, keep calm and forward the rejection to the dev@ mailing list so the project can discuss whether anything needs to be done about it. (If necessary, announce@ mailing list moderators can be contacted via the announce-owner@ handle.)
If this is an X.Y.0 release, update the community support level at the very top of the STATUS files of any branches that have changed support status. This would usually be X.Y.x/STATUS, X.$((Y-1)).x/STATUS, and if the new release is an LTS release, then the oldest supported LTS branch's STATUS file as well.
Update ^/subversion/site/publish/news.html and ^/subversion/site/publish/index.html, uncommenting and adding the link to the release announcement e-mail.
It is then time for the release manager to go and enjoy his $favorite_beverage.
A new release branch is created for each new major and minor release. So, for example, a new release branch is created when preparing to release version 2.0.0, or version 1.3.0. However, when preparing to release 1.3.1 (a patch-version increment), the release branch created at the time of 1.3.0 is used.
If you are preparing for a patch release, then there is no release branch to create. You just pick up where you left off in the current minor version series release branch.
The time at which a new release branch needs to be created is fuzzy at best. Generally, we have a soft schedule of releasing a new minor version every 6 months. So, approximately 4 months after the previous minor release is a good time to start proposing a branch. But remember that this is flexible, depending on what features are being developed.
Review the Roadmap. Should any of the outstanding items be addressed before branching?
Review the incumbent stable branch's STATUS file for outstanding -0 and -1 votes. Was code that is going to be included in the new branch objected to? (Even if yes, that should not block branching, but discussion should be started in order to resolve the issue before rolling release branches.)
Do any tree-wide, mechanical changes. (Non-mechanical changes should have happened earlier to allow for review.) This eases merging later. Examples include stripping trailing whitespace and plugging error leaks and fixing invariants in C headers (another case) and code search and replace. (This is also a good time to do other periodical housekeeping tasks such as static analysis.)
Review new and changed APIs for design and style (e.g. Doxygen mark-up, undocumented parameters, deprecation, public/private status, etc.).
abi-laboratory.pro Subversion may be useful.
Run compatibility tests against the incumbent minor release.
Once people agree that a new release branch should be made, the Release Manager creates it with one of the following procedures (substitute A.B with the version you're preparing, eg. 1.3, or 2.0).
Most of the work to create a release branch can be automated by tools/dist/release.py:
Run this in an empty-ish directory where it will make some temporary checkouts:
release.py --verbose create-release-branch A.B.0
If not done previously, create the release notes template for the project website:
release.py --verbose write-release-notes A.B.0 > .../docs/release-notes/A.B.html svn add .../docs/release-notes/A.B.html svn ci -m "Add release notes template." .../docs/release-notes/A.B.html
Most of the steps in this section can be automated by tools/dist/release.py—see above—but are documented here in case the Release Manager wants to do them manually:
Create the new release branch with a server-side copy:
svn cp ^/subversion/trunk \
^/subversion/branches/A.B.x \
-m "Create the A.B.x release branch."
Edit subversion/include/svn_version.h on trunk and increment the version numbers there. Do not commit these changes yet.
The version number on trunk always reflects the major/minor version that will immediately follow the one for which you just created a branch (eg. 2.1.0 for the 2.0.x branch, and 1.4.0 for the 1.3.x branch).
Edit subversion/bindings/javahl/src/org/apache/subversion/javahl/NativeResources.java on trunk and increment SVN_VER_MINOR. Do not commit these changes yet.
Edit subversion/tests/cmdline/svntest/main.py on trunk and increment SVN_VER_MINOR. Do not commit these changes yet.
Edit CHANGES on trunk to introduce a new section for the upcoming release if it is not already there, and also a new section for the next minor release to be made in the future. Each section starts with:
Version A.B.0
(?? ??? 20XX, from /branches/A.B.x)
https://svn.apache.org/repos/asf/subversion/tags/A.B.0
Leave the release date blank for now. It will remain this way until rolling time.
Commit these changes with a log message something like the following:
Increment the trunk version number to A.$((B+1)), and introduce a new CHANGES
section, following the creation of the A.B.x release branch.
* subversion/include/svn_version.h,
subversion/bindings/javahl/src/org/apache/subversion/javahl/NativeResources.java,
subversion/tests/cmdline/svntest/main.py
(SVN_VER_MINOR): Increment to $((B+1)).
* CHANGES: New section for A.$((B+1)).0.
Create a new STATUS file on the release branch.
Make sure all buildbot builders are building the new release branch.
Add A.B to the MINOR_LINES list in https://svn.apache.org/repos/infra/infrastructure/buildbot/aegis/buildmaster/master1/projects/subversion.conf.
Create a template release-notes document, site/publish/docs/release-notes/A.B.html
Ask someone with appropriate access to add the A.B.x branch to the backport merge bot.
Decide whether the release would be regular or LTS and record the decision in lts_release_lines in tools/dist/release-lines.yaml for release.py.
The backport merge bot runs nightly on the svn-qavm1 machine, under the svnsvn local user account, making commits using the svn-role Subversion account name.
This configuration currently requires someone with admin access to the machine, to manage changes to the set of branches.
The bot merges approved backports on each branch A.B.x for which a WC directory exists at ~svnsvn/src/svn/A.B.x .
The checkout there was created by running (as svnsvn user, e.g. with sudo) something like:
svn checkout --depth=empty https://svn-master.apache.org/repos/asf/subversion/branches ~svnsvn/src/svn svn up ~svnsvn/src/svn/A.B.x # for each supported branch
The repo URL is svn-master.a.o because the backports merger runs svn ci && svn up in a loop, and assumes svn up will update it to the revision it just committed. That's not guaranteed when updating from a mirror (and svn.a.o may point to a mirror). The buildbot slaves do this too, for the same reason.
Each branch is in a subdirectory of the WC root. To add a new branch, populate the source tree with svn up:
sudo -H -u svnsvn svn up ~svnsvn/src/svn/A.B.x
To remove a no-longer-supported branch, use svn up -r0:
sudo -H -u svnsvn svn up -r0 ~svnsvn/src/svn/Z.Z.x
More notes on the setup can be found in machines/svn-qavm1/ and in the Subversion PMC's private repository. There are also historical notes on previous incarnations in the history of machines/.
Once a release branch has been created, no development ever takes place there. The only changes permitted are ones made to various bookkeeping files such as STATUS, and changes merged in from trunk. In rare cases, a feature branch may be created from the A.B.x branch to address issues specific to the release branch (for example, to fix a bug that does not affect trunk).
The protocol used to accept or refuse the merging of changes from trunk is of interest to all Subversion developers, and as such is documented in the release stabilization section.
The CHANGES file is the project changelog file. Before a release, it must be brought up to date to list all changes since the last release.
Below, we describe the manual process. For partial automation, see
release.py write-changelog
For patch-releases, this is fairly easy: you just need to walk through the commit logs for the branch since the last "golden" revision, and note all interesting merges. For minor and major releases, this is more complex: you need to traverse the commit log on trunk since the last release branch was forked, and make note of all changes there. It's the same procedure, but a lot longer, and somewhat more complex as it involves filtering out changesets that have already been backported to previous release branches and released from there.
Remember that CHANGES should always be edited on trunk and then merged over to the release branch(es) when necessary. It is very important that all changes of all releases be documented in the CHANGES file on trunk, both for future reference and so that future release branches contain the sum of all previous change logs.
Keep the bullet point for each change concise, preferably no more than one line long. Sometimes that can be a challenge, but it really adds to the overall readability of the document. Think to yourself: If it takes more than one line to describe, maybe I'm getting too detailed?
Run svn log --stop-on-copy ^/subversion/branches/A.B.x. This should give you every change ever made to the A.B.x line, including backports made to the A.B.x branch. You then need to remove logs of changes that have already been released in micro releases of the previous major/minor branch. Run svn log -q --stop-on-copy on the previous release branch, and then write a script to parse the revnums and remove them from your primary log output. (Karl and Ben used to use emacs macros to do that, but suggest that we write a more general script.) (Update: nowadays, svn mergeinfo --show-revs eligible should simplify obtaining the set of relevant revisions—use the minor branch as the source, and the previous minor branch as the target.)
Read that log from oldest to newest, summarizing points as you go. The trick is to know what level of detail to write at: you don't want to mention every tiny little commit, but you don't want to be too general either. Set your filter-level by reading through a few pages of the CHANGES file before starting on the new section, just to keep things consistent.
As part of release stabilization, CHANGES should be updated as bug fixes are ported to the release branch. Generally, if you merge a revision or group of revisions (i.e., an item in STATUS) to the release branch, you should also add an item to CHANGES on trunk, following the same guidelines outlined above. This list will then be merged to the release branch when a patch release is made.
In practice, CHANGES does not get updated each time a fix is backported to the release branch. Normally, the release manager updates CHANGES as one of the first steps to make a patch release.
A convenient way to get the list of backports that should be mentioned in CHANGES is to use the same tool that populates Coming up in the next patch release on the Subversion website. This is the upcoming.py script in https://svn.apache.org/repos/asf/subversion/site/tools. Run it while the current working directory is the root of a working copy of the minor branch.
For an enlightening case study of the bungled Subversion 1.5 release cycle, see this paper.
Translation has been divided into two domains. First, there is the translation of server messages sent to connecting clients. This issue has been punted for now. Second there is the translation of the client and its libraries.
The gettext package provides services for translating messages. It uses the xgettext tool to extract strings from the sources for translation. This works by extracting the arguments of the _(), N_() and Q_() macros. _() is used in context where function calls are allowed (typically anything except static initializers). N_() is used whenever _() isn't. Strings marked with N_() need to be passed to gettext translation routines whenever referenced in the code. For an example, look at how the header and footer are handled in subversion/svn/help-cmd.c. Q_() is used for messages which have singular and plural version.
Beside _(), N_() and Q_() macros also U_() is used to mark strings which will not be translated because it's in general not useful to translate internal error messages. This should affect only obscure error messages most users should never ever see (caused by bugs in Subversion or very special repository corruptions). The reason for using U_() is to explicitly note that a gettext call was not just forgotten.
When using direct calls to gettext routines (*gettext or *dgettext), keep in mind that most of Subversion code is library code. Therefore the default domain is not necessarily Subversion's own domain. In library code you should use the dgettext versions of the gettext functions. The domain name is defined in the PACKAGE_NAME define.
All required setup for localization is controlled by the ENABLE_NLS conditional in svn_private_config.h (for *nix) and svn_private_config.hw (for Windows). Be sure to put
#include "svn_private_config.h"
as the last include in any file which requires localization.
Also note that return values of _(), Q_() and *gettext() calls are UTF-8 encoded; this means that they should be translated to the current locale being written as any form of program output.
The GNU gettext manual (https://www.gnu.org/software/gettext/manual/html_node/gettext_toc.html) provides additional information on writing translatable programs in its section "Preparing Program Sources". Its hints mainly apply to string composition.
Currently available translations can be found in the po section of the repository. Please contact dev@subversion.apache.org when you want to start a translation not available yet. Translation discussion takes place on that list.
The Makefile build targets locale-gnu-* (used to maintain po files) require GNU gettext 0.13 or newer. Note that this is not a requirement for those wanting to compile the *.po files into *.mo's.
Before starting a new translation please contact the subversion development mailing list to make sure you are not duplicating efforts. Also please note that the project has a strong preference for translations which are maintained by more than one person: mailing the lists with your intentions might help you find supporters.
After that, you should perform the following steps:
./autogen.sh./configuremake locale-gnu-potmsginit --locale LOCALE -o LOCALE.po in the
subversion/po directory of your working copy. LOCALE is
the ll[_LL] language and country code used to identify your locale.Steps (2) and (3) generate a Makefile; step (4) generates
subversion/po/subversion.pot
The Subversion project has a policy not to put names in its files, so please apply the two changes described below.
The header in the newly generated .po file looks like this:
# SOME DESCRIPTIVE TITLE. # Copyright (C) YEAR THE PACKAGE'S COPYRIGHT HOLDER # This file is distributed under the same license as the PACKAGE package. # FIRST AUTHOR <EMAIL@ADDRESS>, YEAR.
Please replace that block with the following text:
# <Your language> translation for subversion package # Licensed to the Apache Software Foundation (ASF) under one # or more contributor license agreements. See the NOTICE file # distributed with this work for additional information # regarding copyright ownership. The ASF licenses this file # to you under the Apache License, Version 2.0 (the # "License"); you may not use this file except in compliance # with the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, # software distributed under the License is distributed on an # "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY # KIND, either express or implied. See the License for the # specific language governing permissions and limitations # under the License.
The first translation block in the .po file contains two lines like these:
"Last-Translator: FULL NAME <EMAIL@ADDRESS>\n" "Language-Team: LANGUAGE <LL@li.org>\n"
Please replace those with these two lines:
"Last-Translator: Subversion Developers <dev@subversion.apache.org>\n" "Language-Team: YOUR LANGUAGE <dev@subversion.apache.org>\n"
To be documented
See issue #1977.
Before submitting to the mailing list or committing to the repository, please make sure your po file 'compiles'. You can do this with these steps (on Makefile based systems):
./autogen.sh./configure (with the appropriate arguments)make localeThe autogen.sh step is important, since it adds new po files as dependencies of the 'locale' build target. Note however that steps 1 and 2 are only needed once after you have added a new translation.
Please don't mail large po files to the mailing lists. There are many subscribers on dev@subversion.apache.org who are on slow links and do not want to receive a large file by email. Instead, place the po file somewhere on the Internet for download, and just post the URL. If you do not have a site available, please ask on dev@ and someone will help you find a location.
Of course, if you have commit access to the Subversion repository, you can just commit the po file there, assuming all other requirements have been satisfied.
The Makefile based part of the build system contains a make target to facilitate maintenance of existing po files. To update po files on systems with GNU gettext run
make locale-gnu-po-update
To only update a particular language, you may use
make locale-gnu-po-update PO=ll
where ll is the name of the po file without the extension (i.e. PO=sv).
It is recommended that the .po update is done by using two commits; one after the "make locale-gnu-po-update", and one after the translation is done. This has two advantages:
gettext(1) produces lots of line number changes which makes
the resulting diff hard to review by the other translators. By committing
twice, all the line number changes are stored in the first commit, and
the second commit contains all the actual translations with no extra
garbage.Editing po files in trunk is pretty straightforward, but gets a bit more
complicated when those changes are going to be transferred to a release
branch. Project policy is to make no direct changes on release branches,
everything that is committed to the branch should be merged from trunk.
This also applies to po files. Using svn merge to do the job
can lead to conflicts and fuzzy messages due to the changes in line numbers
and string formatting done by gettext.
svn
merge to do branch updates. The following rules apply:
make locale-gnu-po-updateThe above list is a complete enumeration of all operations allowed on po files on branches.
Merging messages from trunk revision X of YY.po to your branch working copy can be done with this command:
svn cat -r X ^/subversion/trunk/subversion/po/YY.po | \
po-merge.py YY.po
On some gettext implementations we have to ensure that the mo
files — whether obtained through the project or created
locally — are encoded using UTF-8. This requirement stems
from the fact that Subversion uses UTF-8 internally, some
implementations translate to the active locale
and the fact that bind_textdomain_codeset() is not portable
across implementations.
Some gettext implementations use a section with a msgid "" (empty string) to keep administrative data. One of the headers suggested is the 'Last-Translator:' field. Because the Subversion project has a policy not to name contributors in specific files, but give credit in the repository log messages, you are required not to put your name in this field.
Since some tools require this field to consider the po file valid (i.e. Emacs PO Mode), you can put "dev@subversion.apache.org" into this field.
The Translation Project attempts to organise translation attempts and get translators for various packages. Some teams have guidelines to stimulate consistency across packages.
The project has standardised the use of quotes. Some translation teams have done the same. If there is no translation team for your locale or they did not standardise quoting, please follow the project guidelines elsewhere in this guide. If they did: follow them :-)
Since translators will generally see all error messages in the code, it's important to know that there is a special section in this document about this category of strings. Here the same applies as does for the quotes: Adhere to them on all points for which there is no explicit policy set out by the translation team for your language.